
Sony has big ambitions in the cloud gaming sector. Currently, PlayStation is conducting tests to run real-time game servers from the cloud using Kubernetes.
This is a challenging endeavor because Kubernetes “pods,” which are small computing units, are typically temporary and have the potential to disrupt the gaming experience if automatically stopped and relaunched, resulting in a bad gaming experience.
Job postings ALSO suggest Sony is working on new hybrid cloud infrastructure with Kubernetes and AWS.
How is Sony tackling this challenge
During a talk at Kubecon, Joe Irving, a senior DevOps engineer at PlayStation, proposed a seemingly simple answer to this complex issue: Agones.
Agones
Agones is an open-source project that originated in 2017 through a collaboration between Ubisoft and Google Cloud. Its purpose was to develop a:
“turn-key solution for running, scaling, and orchestrating multiplayer dedicated game servers on top of Kubernetes.”
Joe Irving
Irving eloquently explained the significance and function of game servers. A game server serves as a central source of truth for a multiplayer game.
As Irving emphasized, some might perceive running game servers on Kubernetes as a flawed idea that wouldn’t work effectively out of the box.
He pointed out challenges related to resource allocation in Kubernetes, such as terminating underutilized compute units using the cluster autoscaler or dynamically adjusting resources during deployments or patch updates. These challenges involve the need to keep the system running smoothly while breaking up and reallocating compute resources dynamically to provide support.
Why Agones?
Agones offers a library for hosting, running, and scaling dedicated game servers on Kubernetes, thereby reducing development and operational costs associated with hosting, scaling, and orchestrating multiplayer game servers.
Agones supports hosting game servers anywhere—whether in the cloud, on-premises, or on local machines—and can accommodate any Linux-compatible game server, regardless of programming language or dependencies, according to the project’s leaders.
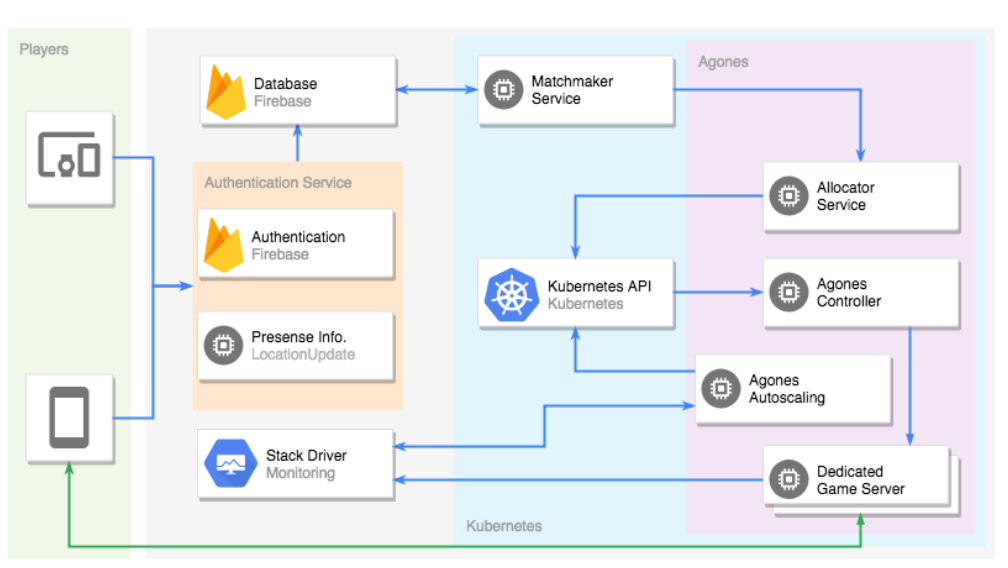
Agones provides all the scalability, flexibility, and cloud-native capabilities required for game servers.
With the gaming industry projected by PwC to be worth $321 billion by 2026 and various companies, from Netflix to Amazon, expanding their gaming offerings, cloud providers are eager to support infrastructure for cloud gaming, streaming and multi-player game-handling workloads. There’s a lucrative opportunity in this domain, although a few challenges remain.
If PlayStation successfully implements the gamerserver-on-Kubernetes + Agones approach (and Irving’s team is actively hiring to realize this vision), the market will witness a greater frequency of multi-player games being released. This is excellent news for both game developers and gamers. Keep an eye on this space.
Sony and cloud gaming
Sony is actively pursuing patents for techniques that allow the sharing of a single GPU across multiple applications. This innovation could address the economic challenges associated with cloud gaming, as traditionally, each player required a dedicated remote computer.
The patent applications shed light on Sony’s efforts to enable various capabilities, including pausing and resuming games in the cloud, seamless transition of games across different devices, streaming games to web browsers, handling unreliable cellular internet connections, and more. By securing these patents, Sony aims to enhance the cloud gaming experience and overcome existing limitations.