Summary
Generative AI has moved fast. Many organizations in the UAE already have chatbots, copilots, or proof-of-concept demos in place. The real challenge starts after that initial success.
Turning generative AI into a reliable, scalable, and governed production capability is where most teams struggle. Models behave differently from traditional ML. Outputs are probabilistic. Costs can spike quickly. And without the right operational setup, even strong use cases fail to gain trust.
In this article, we’ll walk through how to operationalize generative AI using a cloud-native MLOps approach. You’ll learn what makes GenAI MLOps different, how to design scale and governance, and what practical steps help UAE organisations move from experimentation to production with confidence.
Why Operationalizing Generative AI Matters for UAE Organisations
Across the UAE, generative AI is being explored in government services, financial institutions, logistics, real estate, and large enterprises. These environments share a few common expectations: reliability, security, clear accountability, and predictable costs.
Many GenAI initiatives stall because they are treated like short-lived experiments. A demo that works once does not mean the system can handle real users, real data, and real scrutiny.
Operationalizing generative AI means building systems that:
- Produce consistent and explainable outputs
- Scale with demand without surprises
- Meet security and compliance expectations
- Can be monitored, improved, and audited
Cloud platforms such as Amazon Web Services (AWS) provide the foundation for this, but only if teams apply MLOps principles designed for generative workloads. AWS offers a suite of tools, such as Amazon SageMaker for model deployment and training, AWS Lambda for serverless functions, and Amazon S3 for scalable storage, that help accelerate operationalization.
What Does “Operationalizing Generative AI” Really Mean?
Operationalizing generative AI is about repeatability and trust.
Instead of running prompts manually or deploying models as one-off services, teams build pipelines that manage the full lifecycle. This includes experimentation, deployment, monitoring, evaluation, and improvement.
Generative AI changes the rules in a few important ways:
- Prompts become first-class assets, just like code
- Outputs vary, even for the same input
- User feedback becomes part of the learning loop
Because of this, GenAI MLOps focuses less on static accuracy and more on quality, consistency, safety, and cost control.
How MLOps for Generative AI Differs from Traditional MLOps
Traditional MLOps often revolve around training a model, measuring accuracy, and deploying it behind an API. Generative AI introduces additional layers.
You now manage:
- Foundation models or hosted APIs
- Prompt templates and configurations
- Embeddings and vector databases
- Retrieval pipelines for context
- Evaluation workflows that include human and AI reviewers
Another key difference is non-determinism. Two calls to the same model can produce different results. That means teams must think carefully about versioning, evaluation, and rollback.
Cloud-native design helps here. Decoupling components allows teams to change prompts or models without rewriting applications.
Core Principles of Cloud-Native MLOps for Generative AI
Automation First
Manual deployments do not scale. Cloud-native MLOps relies on automation for infrastructure, pipelines, and releases. AWS services like AWS CodePipeline and Amazon SageMaker can automate deployment, while AWS CloudFormation can handle infrastructure as code. With these services, teams can quickly scale operations and maintain consistency across different environments.
This includes:
- Infrastructure as Code for environments
- CI/CD pipelines for models, prompts, and workflows
- Consistent setups across development, testing, and production
Automation reduces errors and speeds up iteration without sacrificing control.
Decoupling Models from Applications
Treat models as services, not embedded logic. Applications should not depend on a specific model version or provider.
This approach:
- Reduces vendor lock-in
- Makes upgrades safer
- Supports multi-model or multi-region strategies
Built-In Observability
If you cannot observe a GenAI system, you cannot trust it.
Teams should track:
- Latency and availability
- Error and failure rates
- Token usage and cost
- Output quality signals
Observability should exist from day one, not as an afterthought.
Reference Architecture for Cloud-Native GenAI MLOps
A typical cloud-native GenAI MLOps architecture separates the control plane from the execution plane. For deployment and orchestration, AWS services like Amazon SageMaker for model training and deployment, and AWS Lambda for serverless compute, can be integrated into the CI/CD pipelines. These services help manage model versions and ensure scalability without vendor lock-in.
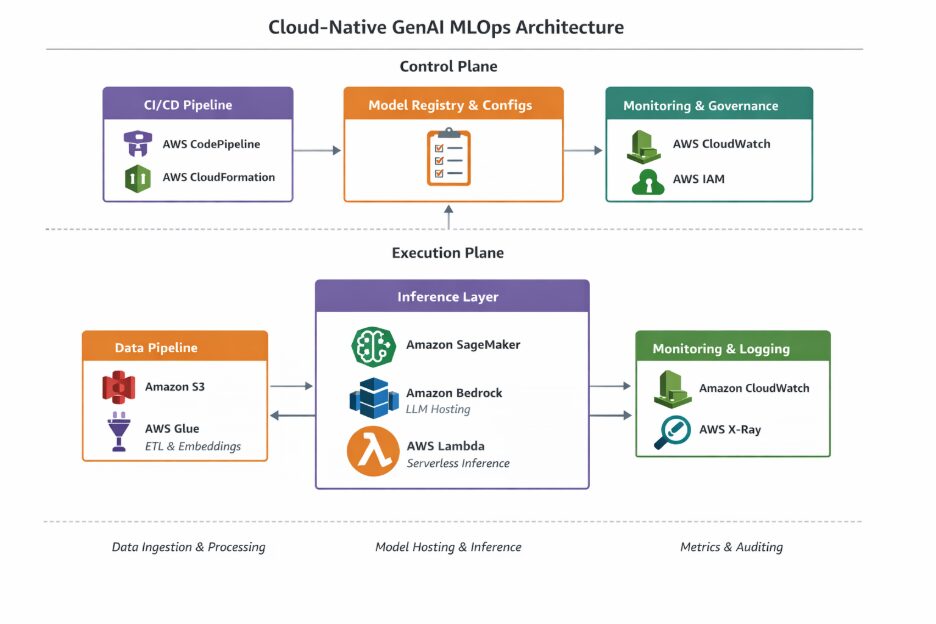
At a high level:
- The inference layer handles model access and requests
- Data pipelines manage ingestion, embeddings, and retrieval
- CI/CD pipelines manage releases and configuration changes
- Monitoring and governance layers provide visibility and control
This separation allows teams to scale components independently and apply security policies consistently.
Managing the End-to-End GenAI Lifecycle
Experimentation and Prompt Engineering at Scale
Prompt engineering is not a one-time task. Teams experiment constantly to improve relevance, tone, and accuracy.
Operational maturity requires:
- Versioning prompts and templates
- Tracking experiments and outcomes
- Reproducing results when needed
Without this, teams struggle to explain why behaviour changed.
Choosing Between RAG, Few-Shot, and Fine-Tuning
Not every use case needs fine-tuning.
- Few-shot prompting works well for simple tasks
- Retrieval-Augmented Generation (RAG) helps when responses must reference internal data
- Fine-tuning makes sense for specialised language or strict formats
Each option has trade-offs in cost, complexity, and control. MLOps pipelines should support all three without friction.
Reliable Deployment and Inference
Production GenAI systems must handle traffic spikes and unpredictable usage.
Techniques such as canary releases and blue/green deployments allow teams to introduce changes safely. Online inference suits real-time use cases, while batch inference works well for reporting or analysis of jobs.
Evaluating Generative AI Outputs Beyond Accuracy
Evaluating GenAI is harder than scoring predictions.
Teams often combine:
- Automated metrics for similarity or correctness
- LLM-based evaluators for relevance and faithfulness
- Human review for critical workflows
The goal is not perfection, but early detection of issues and continuous improvement.
Security, Governance, and Compliance
Identity and Access Management
Different teams need different levels of access. ML engineers, platform teams, and application developers should not share the same permissions.
Role-based access and environment isolation reduce risk and simplify audits.
Data Protection and Responsible AI
Prompts, outputs, and embeddings can contain sensitive data. Encryption and careful data handling are essential.
Responsible AI practices such as content filters and policy checks help prevent misuse and build trust, especially in regulated UAE industries.
Auditability and Change Control
Security and governance are crucial for any GenAI implementation. Using AWS IAM (Identity and Access Management), teams can enforce role-based access control, segregating duties between ML engineers, platform teams, and application developers to minimize risk. This also helps in ensuring that all changes are logged and tracked for audit purposes
This level of traceability supports internal governance and external compliance.
Cost Optimization for Scalable GenAI Deployment
Generative AI costs can grow quickly without proper control. AWS helps teams optimize costs through services like AWS Cost Explorer, which enables detailed cost tracking and forecasting. Additionally, AWS Lambda for serverless inference can reduce over-provisioning of compute resources, thus helping keep costs in check.
Common cost drivers include inference calls, large contexts, and orchestration overhead. Teams can manage costs by:
- Caching repeated responses
- Reducing unnecessary context
- Choosing asynchronous processing where possible
Visibility into usage patterns helps teams make informed trade-offs.
Common Pitfalls to Avoid
Several issues appear repeatedly in struggling projects:
- Treating GenAI like traditional ML
- Ignoring prompt and pipeline versioning
- Scaling before governance is ready
- Lacking insight into quality and spend
Avoiding these mistakes saves time and credibility.
A Practical Readiness Check
Before scaling, ask:
- Can we explain and audit outputs?
- Do we control access and data usage?
- Are costs visible and predictable?
- Can we roll back changes safely?
If the answer is no, it’s time to strengthen the MLOps foundation.
How SUDO Consultants Helps
SUDO Consultants works with organisations across the UAE to design cloud-native MLOps platforms for generative AI. We help teams move from experimentation to production with confidence by focusing on architecture, governance, and long-term scalability.
Final Thoughts
Generative AI delivers value only when it works reliably at scale. Cloud-native MLOps provides the structure needed to make that happen.