
In today’s digital-first world, legal teams grapple with lengthy, intricate policy documents that are vital for compliance but tedious to process. Automating the summarization of these documents can save time, improve accuracy, and streamline decision-making. This blog demonstrates how to build a serverless function for policy document summarization using AWS Lambda and Amazon Bedrock’s generative AI model, Amazon Titan T1 Express.
Use Case Overview
In this blog post, I will guide you through a use case: The Policy Document Summarizer. This solution generates concise summaries of complex policy documents, customized to meet specific compliance requirements. It retrieves documents stored in Amazon S3, processes them using AWS Lambda, and utilizes Amazon Titan T1 Express to create high-quality, domain-specific summaries. The resulting summaries are then stored back in Amazon S3 for easy access and retrieval.
We will build a serverless solution using AWS Lambda to summarize legal policy documents. The system will:
- Store policy documents in an S3 bucket.
- Trigger a Lambda function when a new document is uploaded.
- Use Amazon Bedrock to generate concise, industry-specific summaries.
- Store summarized text back in S3.
Why Not a Simple LLM Call?
This solution integrates AWS services to process, summarize, and store documents dynamically. Unlike a direct LLM interaction, it ensures secure, scalable, and repeatable workflows with automated input/output handling and customizable configurations.
Prerequisites
Before you begin you need:
- An aws account with a full administrative privileges
- Python runtime environment
- AWS Command Line Interface (CLI)
Step 1: Set Up S3 to store the policy documents:
- Create an S3 Bucket:
- Go to the AWS Management Console and search for S3
- Click Create Bucket.
- Give the bucket a name like policy-doc-storage.
- Uncheck “Block all public access” if you need external access (optional).
- Leave other settings as default and click Create bucket.
- Create an Input Folder:
- Inside the S3 bucket, create a folder named input/.
- This is where you will upload the policy documents.
- Create an Output Folder (optional):
- Create another folder named output/.
- Summarized results will be saved here if needed.
- Upload Sample Documents:
- Use the Upload button to upload your .txt policy files into the input/ folder.
Step 2: Create IAM Role for Lambda
Before writing the code, create an IAM role for the Lambda function with the following permissions:
- Go to IAM from the AWS Console
- From the navigation panel on the left select Roles
- Click ‘Create Role’ button.
- Select Lambda as the trusted entity.
- Search and attach the following policies:
- AmazonS3FullAccess (Allows the Lambda function to read/write to the S3 bucket)
- AmazonBedrockFullAccess (Allows the Lambda function to invoke models)
- AWSLambdaBasicExecutionRole (Allows basic Lambda Execution)
- I will name the role ‘lambda-policy-summarizer-role’ and save.
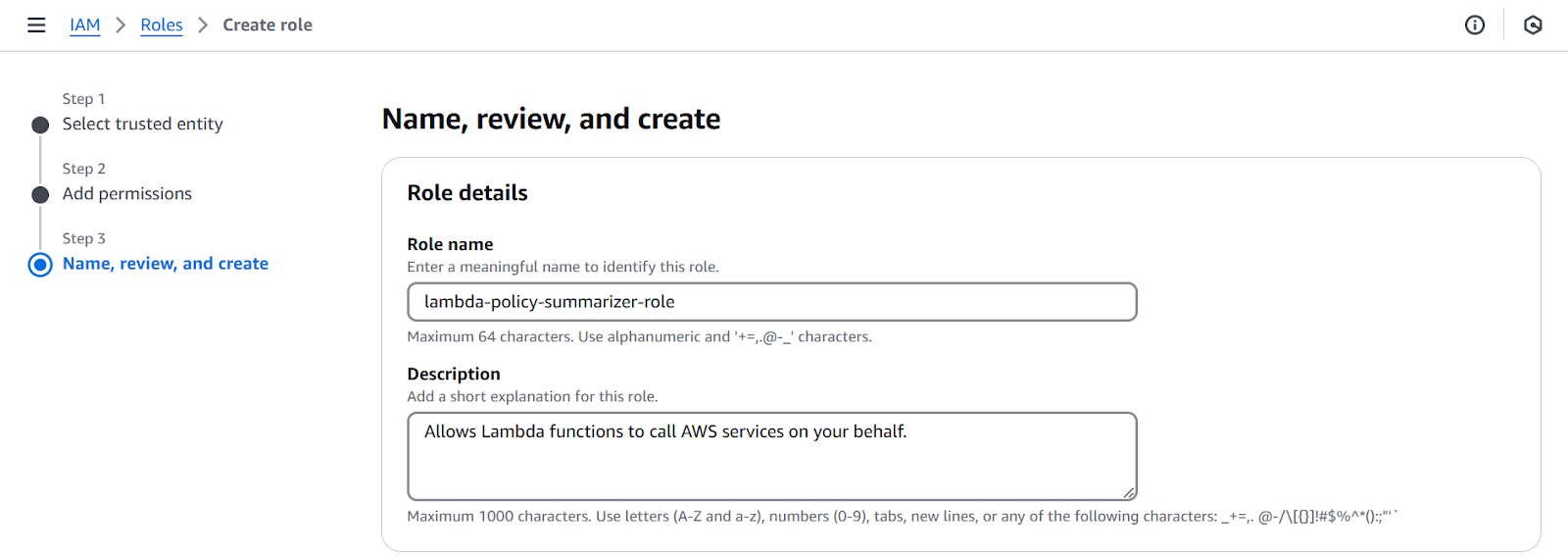

Screenshot of IAM Role Creation
Step 3: Create Lambda Function
Now, create the Lambda function.
- From the AWS Console select AWS Lambda
- Click ‘Create Function’.
- Select ‘Author from scratch’.
- I will name our Lambda function ‘policy-document-summarizer’.
- Select Runtime: Python 3.9 or newer.
- On the ‘Change default execution role’ section select ‘use an existing role’ option and Attach the role ‘lambda-policy-summarizer-role’ we created in step 2.
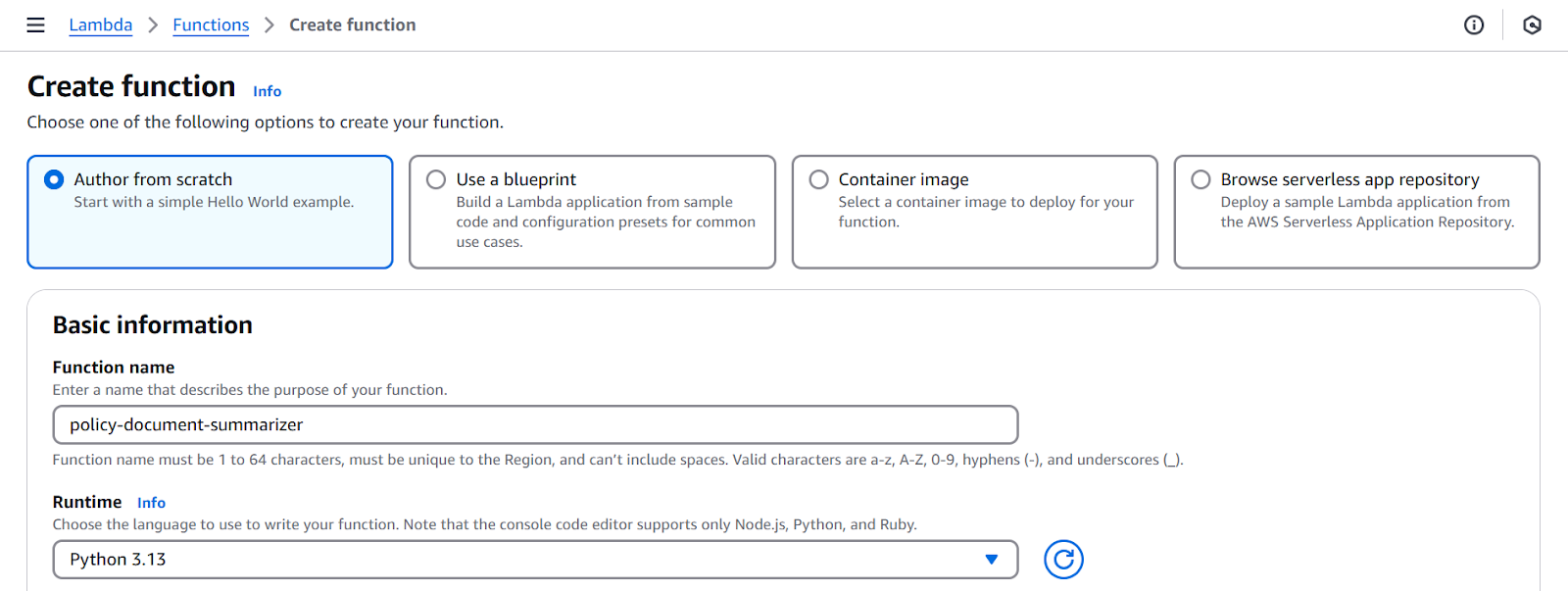
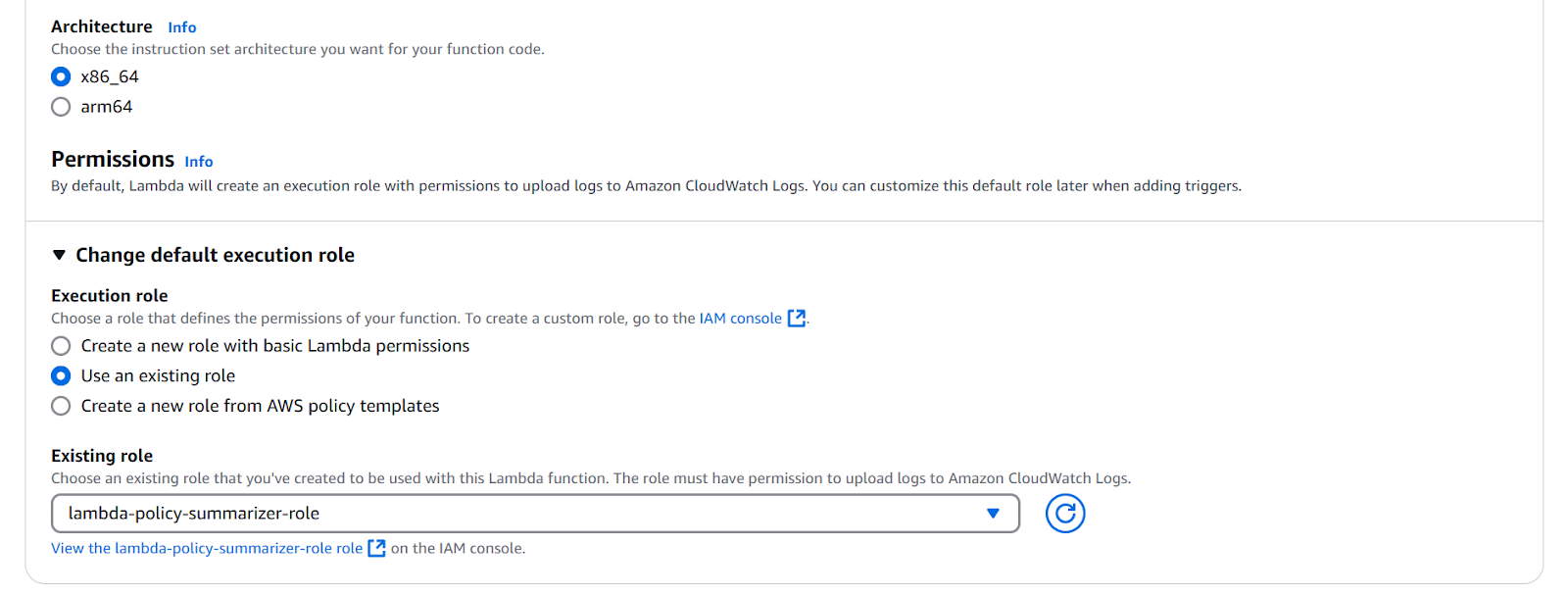
Screenshot of Lambda function creation
- Next, write a Python Function that fetches text from an S3 bucket and calls the summarizer model:
Here is the Python code:
import boto3
import json
import logging
logging.basicConfig(level=logging.INFO)
logger = logging.getLogger()
bedrock = boto3.client("bedrock-runtime", region_name="us-east-1")
s3 = boto3.client("s3")
def fetch_text_from_s3(bucket_name, object_key):
try:
logger.info(f"Fetching text from S3 bucket '{bucket_name}', key '{object_key}'...")
response = s3.get_object(Bucket=bucket_name, Key=object_key)
content = response["Body"].read().decode("utf-8")
if not content:
raise ValueError("S3 object is empty.")
logger.info("Successfully fetched text from S3.")
return content
except Exception as e:
logger.error(f"Error fetching text from S3: {e}")
raise
def summarize_text_with_bedrock(input_text):
"""
Summarizes the given text using Amazon Bedrock.
"""
try:
logger.info("Sending text to Bedrock for summarization...")
payload = {
"inputText": input_text
}
response = bedrock.invoke_model(
modelId="amazon.titan-tg1-large",
contentType="application/json",
accept="application/json",
body=json.dumps(payload)
)
summary_response = json.loads(response["body"].read().decode("utf-8"))
summary = summary_response.get("results", [{}])[0].get("outputText", "")
if not summary:
raise ValueError("Bedrock response does not contain a summary.")
logger.info("Successfully generated summary using Bedrock.")
return summary
except Exception as e:
logger.error(f"Error summarizing text with Bedrock: {e}")
raise
def save_text_to_s3(bucket_name, object_key, text_content):
try:
logger.info(f"Saving text to S3 bucket '{bucket_name}', key '{object_key}'...")
s3.put_object(
Bucket=bucket_name,
Key=object_key,
Body=text_content,
ContentType="text/plain"
)
logger.info("Successfully saved text to S3.")
except Exception as e:
logger.error(f"Error saving text to S3: {e}")
raise
def lambda_handler(event, context):
try:
bucket_name = event.get("bucket_name")
object_key = event.get("object_key")
if not bucket_name or not object_key:
raise ValueError("S3 bucket name or object key is missing in the event.")
text_content = fetch_text_from_s3(bucket_name, object_key)
max_length = 5000 # Bedrock input limit
truncated_text = text_content[:max_length]
summary = summarize_text_with_bedrock(truncated_text)
output_key = f"output/{object_key.split('/')[-1].replace('.txt', '_summary.txt')}"
save_text_to_s3(bucket_name, output_key, summary)
return {
"statusCode": 200,
"body": {
"summary": summary,
"output_key": output_key,
"message": f"Summarized text saved to 's3://{bucket_name}/{output_key}'"
},
}
except Exception as e:
logger.error(f"Error in Lambda function: {e}")
return {
"statusCode": 500,
"body": f"Error: {str(e)}"
}Let’s break down the key code blocks:
Imports:
import boto3
import json
import loggingThis code begins by importing three essential libraries. The first is boto3, the AWS Software Development Kit (SDK) for Python, which allows the function to interact with AWS services such as Amazon S3 for fetching files and Amazon Bedrock for performing text summarization tasks—next, json for handling JSON data. Lastly, the logging library is imported to enable the creation of detailed log messages, helping track the execution flow and debug issues effectively. Together, these imports set up the foundation for integrating AWS services, external APIs, and logging capabilities in the function.
Logging:
logging.basicConfig(level=logging.INFO)
logger = logging.getLogger()This code snippet sets up logging for the Python script, enabling the function to track and record its operations. The line logging.basicConfig(level=logging.INFO) configures the logging system to capture messages at the INFO level and above, ensuring that informational messages, warnings, errors, and critical issues are logged. The line logger = logging.getLogger() creates a logger object, which is used throughout the script to emit log messages. This setup is essential for monitoring the execution flow of the Lambda function, helping developers understand its steps and debug any issues. For example, it logs actions such as fetching text from S3, sending requests to Amazon Bedrock, and handling exceptions, providing clear insights for troubleshooting serverless applications.
Setting Up the Bedrock Client:
bedrock = boto3.client("bedrock-runtime", region_name="us-east-1")
s3 = boto3.client("s3")Here, we initialize Amazon S3 and Bedrock clients.
Fetching Text from S3:
def fetch_text_from_s3(bucket_name, object_key):
try:
logger.info(f"Fetching text from S3 bucket '{bucket_name}', key '{object_key}'...")
response = s3.get_object(Bucket=bucket_name, Key=object_key)
content = response["Body"].read().decode("utf-8")
if not content:
raise ValueError("S3 object is empty.")
logger.info("Successfully fetched text from S3.")
return content
except Exception as e:
logger.error(f"Error fetching text from S3: {e}")
raiseThis code retrieves a file’s content stored in an Amazon S3 bucket. Using the boto3 library, it connects to the S3 service, fetches the file using the bucket name and its unique key, and reads the file’s content. It then decodes the file into a human-readable text format. This step ensures that the policy document stored in S3 is ready for summarization.
Sending Text to Bedrock for Summarization:
def summarize_text_with_bedrock(input_text):
try:
logger.info("Sending text to Bedrock for summarization...")
payload = {
"inputText": input_text
}
response = bedrock.invoke_model(
modelId="amazon.titan-tg1-large",
contentType="application/json",
accept="application/json",
body=json.dumps(payload)
)
summary_response = json.loads(response["body"].read().decode("utf-8"))
summary = summary_response.get("results", [{}])[0].get("outputText", "")
if not summary:
raise ValueError("Bedrock response does not contain a summary.")
logger.info("Successfully generated summary using Bedrock.")
return summary
except Exception as e:
logger.error(f"Error summarizing text with Bedrock: {e}")
raiseThis code snippet defines a function that interfaces with Amazon Bedrock to summarize the input text. It constructs a JSON payload with the text to be summarized and invokes the model using the invoke_model method. The response is parsed to extract the summarized text. If no summary is returned, the function raises a ValueError. Extensive logging ensures that both successful and failed operations are recorded for transparency.
Saving Summarized Text to S3:
def save_text_to_s3(bucket_name, object_key, text_content):
try:
logger.info(f"Saving text to S3 bucket '{bucket_name}', key '{object_key}'...")
s3.put_object(
Bucket=bucket_name,
Key=object_key,
Body=text_content,
ContentType="text/plain"
)
logger.info("Successfully saved text to S3.")
except Exception as e:
logger.error(f"Error saving text to S3: {e}")
raiseAfter summarizing the text, this function saves the output to an S3 bucket in a specified “output” folder. It takes the bucket name, object key (file path for saving), and summarized text as inputs. The ‘put_object’ method writes the text to S3 with a plain text content type. This ensures the output is stored securely and is easily accessible for later use.
Lambda Handler Function:
def lambda_handler(event, context):
try:
bucket_name = event.get("bucket_name")
object_key = event.get("object_key")
if not bucket_name or not object_key:
raise ValueError("S3 bucket name or object key is missing in the event.")
text_content = fetch_text_from_s3(bucket_name, object_key)
max_length = 5000 # Bedrock input limit
truncated_text = text_content[:max_length]
summary = summarize_text_with_bedrock(truncated_text)
output_key = f"output/{object_key.split('/')[-1].replace('.txt', '_summary.txt')}"
save_text_to_s3(bucket_name, output_key, summary)
return {
"statusCode": 200,
"body": {
"summary": summary,
"output_key": output_key,
"message": f"Summarized text saved to 's3://{bucket_name}/{output_key}'"
},
}
except Exception as e:
logger.error(f"Error in Lambda function: {e}")
return {
"statusCode": 500,
"body": f"Error: {str(e)}"
}This is the main function that coordinates the process. It extracts the S3 bucket name and object key from the event input, ensuring these values are provided. It calls fetch_text_from_s3 to retrieve the file content and truncates the text to ensure it fits Bedrock’s input size limit. Next, it calls summarize_text_with_bedrock to generate the summary and saves the result to S3 using save_text_to_s3. Finally, the function returns a success response with the summary, output file location, and a confirmation message.
Step 4: Configure S3 Event Trigger
Link the Lambda function to the S3 bucket so it triggers automatically when a file is uploaded.
- Go to S3 and choose your bucket
- Select Properties tab
- Find Event notifications section and Under Event Notifications click Create Event Notification.
- Configure as:
- Event Name: summarize-policy-doc.
- Event Type: All object create events.
- Prefix: input/.
- Destination: Lambda Function → Choose policy-document-summarizer.

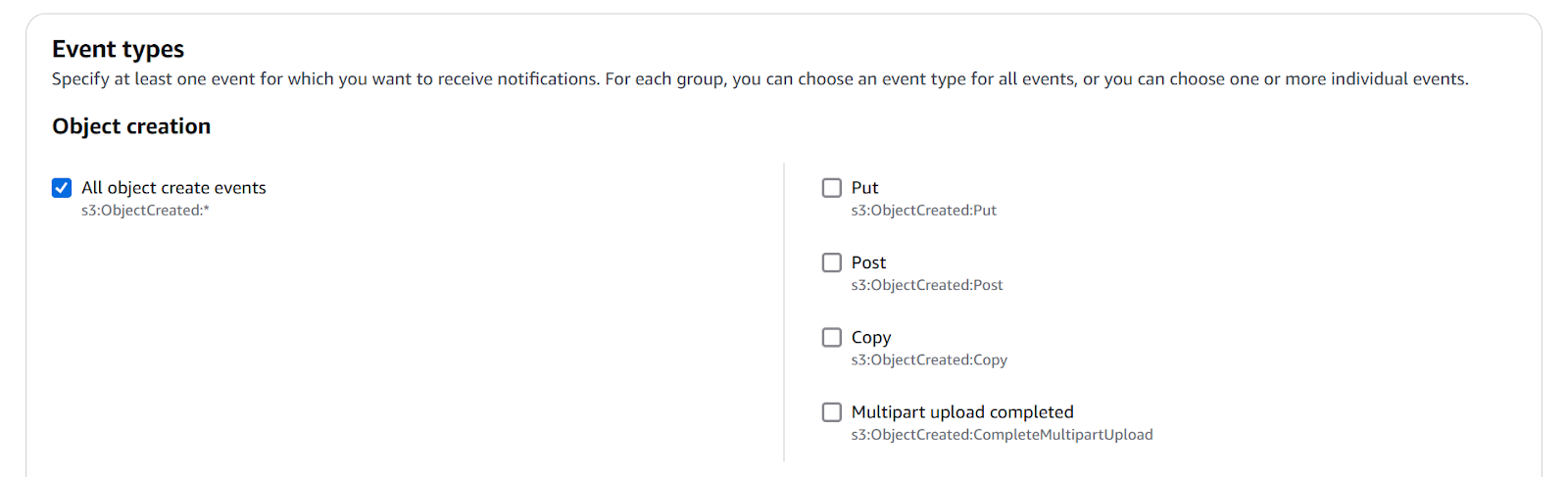
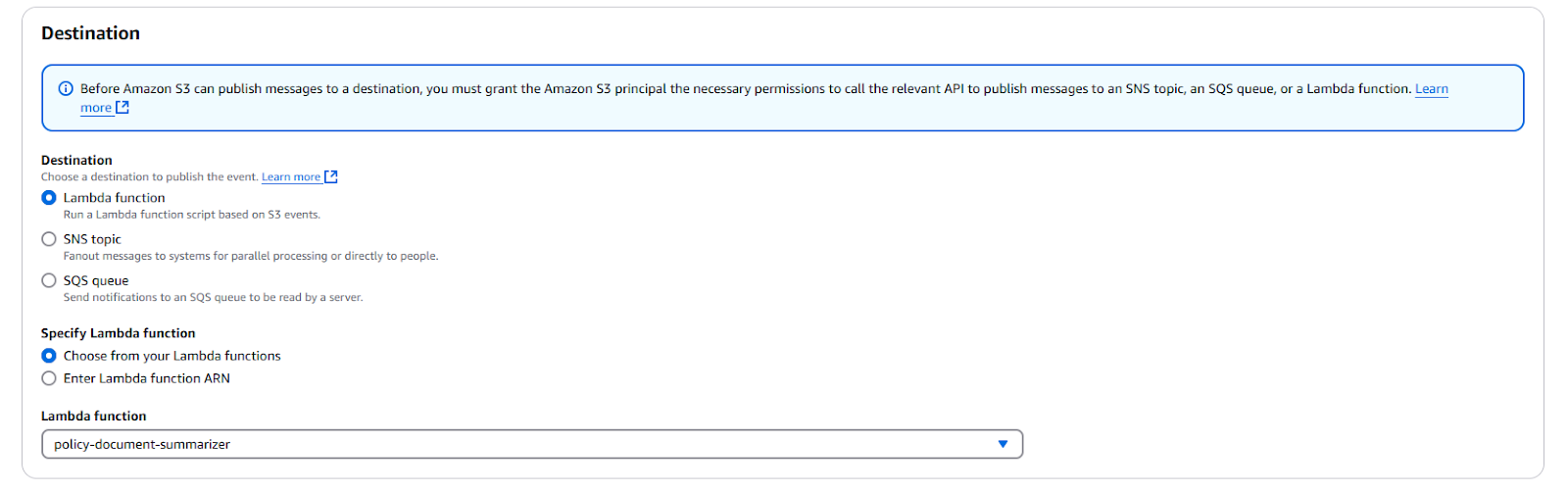
Screenshot of S3 event notification creation
Step 5: Test the System:
- Go back to Amazon S3
- From the navigation panel on the left choose ‘General purpose buckets’
- Choose our bucket ‘policy-doc-storage’
- Select the ‘input’ folder and click upload button
- Click Add file
- Browse and upload the policy document you want to be summarized
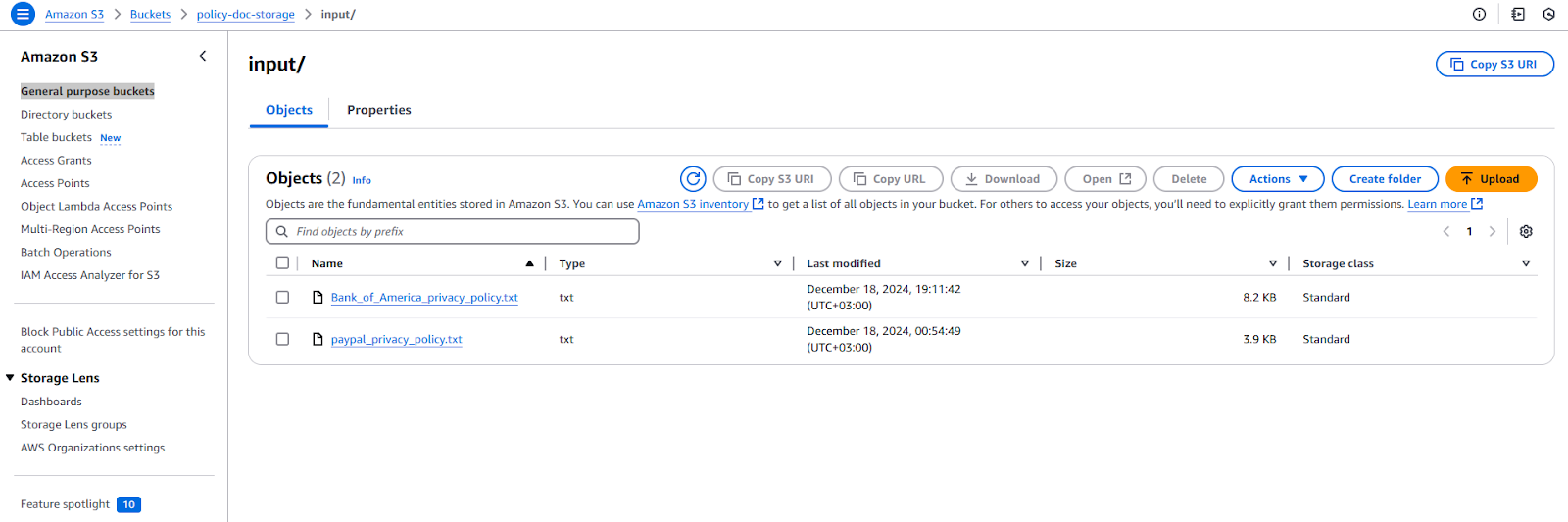
Screenshot of uploaded files in policy-doc-storage bucket’s input folder on S3
- Check the output/ folder in the S3 bucket for the summarized file. Equal number of files should be automatically generated.
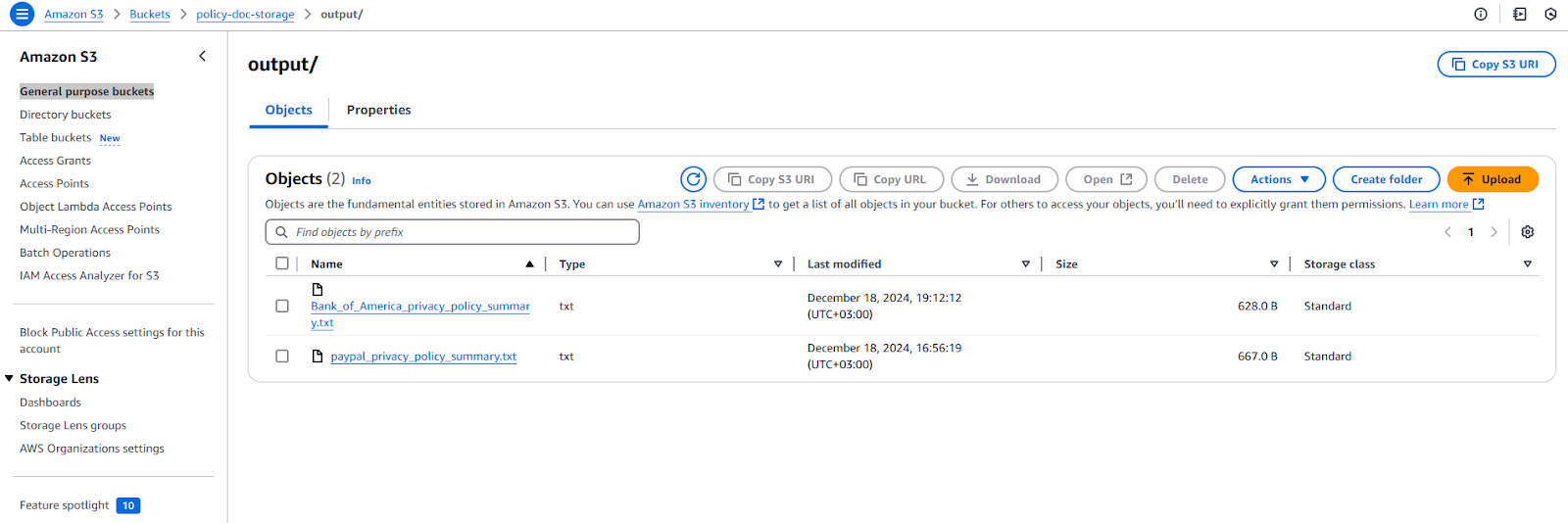
Screenshot of summarized files in policy-doc-storage bucket’s output folder on S3
Conclusion
By leveraging AWS Lambda and Amazon Bedrock, this serverless solution efficiently summarizes lengthy policy documents, saving time and reducing complexity for legal professionals. The integration with S3 ensures a seamless workflow, making this system a scalable and reusable tool for real-world applications.