Introduction to Docker Containerization for SageMaker
From the past couple of years, Docker has proved itself to be a fundamental technology in the world of software deployment and development. In a nutshell, Docker is basically a platform which is provided to the developers so that they can package the applications along with their dependencies into units known to be as containers. All the essential things that are required to run an application are included in these containers like runtime, libraries, code and system tools.
Brief Overview of Docker and its Role in Containerization
One thing to know when dealing with Docker is that it heavily involves the concept of containerization. It is often confused with virtualization. Well, containerization is a lightweight version of virtualization. Virtual machines or VMs are configured to run separate operating system instances whereas the containers share the system’s kernel. They even offer faster speed, great portability and less use of the resources.
Moreover, containers offer reproducibility and consistency that helps developers to build and run the applications smoothly on various platforms. Docker has sure become the standard for containerization in the industry.
Introduction to Amazon SageMaker and its Capabilities
Now let us have a quick overview regarding SageMaker, shall we? Well, Amazon SageMaker is a machine learning service that AWS provides to its users. It assists data scientists and developers to build, train and deploy machine learning models without tensing about the infrastructure complexities. SageMaker offers the following things.
- Built-in frameworks and algorithms.
- AutoML functionality, Hyperparameter tuning as well as model deployment.
- Support for distributed training.
- Integration with other AWS services.
Amazon Elastic Container Registry (ECR)
Amazon Elastic Container Registry or ECR is an AWS service that helps in storing and managing the Docker container images within the AWS infrastructure. You will be offered with a central hub that will help you in storing container images. Afterwards, it can be integrated with other AWS services including Amazon Elastic Kubernetes Service (EKS), Amazon SageMaker and Amazon Elastic Container Service (ECS).
Key Features of ECR
The key features which are provided by Amazon Elastic Container Registry includes:
- Robust Security Means
- Scalability
- Seamless Integration with AWS services
- Lifecycle Policies for Image Management
- IAM Integration for limited access control
Setting up Amazon ECR
In case you are wondering how to set up Amazon ECR then you need to follow the following steps.
- Access the AWS Management Console and head towards ECR.
- Create a new repository by clicking on “Create Repository” option.
- Name the repository and configure its settings like encryption, access permissions and image scanning.
- Upload the Docker container images to ECR using third-party tools like Jenkins, GitLab or with the help of Docker CLI.
- Tag the local Docker images with ECR repository URI.
- Push images to the repository.
Creating a Custom Dockerfile for Amazon SageMaker
A Dockerfile for Amazon SageMaker basically contains all the configuration that is needed for training within the containerized environment. You will get base images from SageMaker which are tailored for ML libraries such as Scikit-Learn, TensorFlow and PyTorch. All the package installations and configurations must be done by the developers.
Example Dockerfile Configuration for SageMaker
Below is the example of Dockerfile configuration made for SageMaker using Python-based workload.
# Use SageMaker TensorFlow base image as the base image
FROM 763104351884.dkr.ecr.us-west-2.amazonaws.com/tensorflow-training:2.6.0-gpu-py38
# Install additional dependencies
RUN pip install pandas scikit-learn
# Set the working directory
WORKDIR /opt/ml/code
# Copy the training script into the container
COPY training.py /opt/ml/code/training.py
# Set the entry point for the container
ENTRYPOINT ["python", "/opt/ml/code/training.py"]Introduction to AWS Step Functions
AWS Step Functions is an AWS serverless service. Its purpose is to coordinate and automate the workflows that include various AWS services, serverless functions and microservices. You can design complex stateful workflows using AWS Step Functions.
Key Features of AWS Step Functions
Following are the key points of AWS Step Functions.
It allows defining and executing multi-step workflows with the help of conditional branching.
There is no need to manage infrastructure as AWS Step Function is a serverless service. It handles the workload using automatic scaling.
Step functions integrate with other AWS services seamlessly.Troubleshooting Common Issues and Errors in Workflow Execution
Common issues and errors faced in the workflow execution includes:
Permission Issues
Make sure that IAM roles and permissions which are associated with Step Functions workflow and SageMaker jobs have necessary permissions to access AWS services and resources.
Input Data Errors
Verify the input data which is provided to the workflow is correctly formatted or not. It should follow all the data validation checks and must be accessible from the specified S3 locations.
Script Errors
Debug the errors generated by SageMaker processing jobs or custom processing scripts. Identify the root cause by checking log files and error messages.
Resource Constraints
In case the resource constraints are causing job failures or bottlenecks, you will have to increase the resource allocations for SageMaker processing jobs.
Network Connectivity
The communication between services should be error-free and restrictions-free. You can further check the connectivity between Step Functions, SageMaker and other AWS services.
Real-World Use Cases and Examples
Real-world examples include:
Predictive Maintenance
Use step functions to make a machine learning pipeline for predictive maintenance. In this pipeline, the SageMaker processing steps preprocess the sensor data, train the model and deploy them for real-time inference.
Image Classification
Use Step Functions to build a workflow for the purpose of automating image classification tasks. Preprocess the image data, train CNNs on labeled datasets and deploy them for classifying the images.
Natural Language Processing (NLP)
Construct a workflow concerning NLP tasks using SageMaker processing steps and Step Functions. Preprocess the textual data, train the models and deploy them for analyzing any unstructured data.
These real time examples and use cases explain the versatility and strength of integrating Docker, SageMaker and Functions to build useful machine learning workflows.
Real World Applications of Custom Docker Containers in SageMaker
Real world applications of custom Docker containers in SageMaker includes:
- Healthcare Diagnostics Platform
- Financial Fraud Detection
- Manufacturing Quality Control
- Energy Sector Predictive Maintenance
Creating Docker Container Image for Amazon SageMaker
This section deals with the guide of how to create a Docker container image for Amazon SageMaker. By storing your custom algorithms in a container you are allowed to run almost any code present in the SageMaker environment regardless of framework, dependencies or programming language.
In this particular example, custom Docker image is stored in Amazon ECR. The step functions use the container to run a Python SageMaker processing script. The container then exports the model to Amazon S3.
Prerequisites and Limitations
Following are the prerequisites.
- An active AWS account
- A SageMaker AWS Identity and Access Management (IAM) role with Amazon S3 permissions
- An IAM execution role for Step Functions
- Familiarity with Python
- Familiarity with Amazon SageMaker Python SDK
- Familiarity with the AWS Command Line Interface (AWS CLI)
- Familiarity with AWS SDK for Python (Boto3)
- Familiarity with Amazon ECR
- Familiarity with Docker
Following are the limitations.
- AWS Step Functions Data Science SDK v2.3.0
- Amazon SageMaker Python SDK v2.78.0
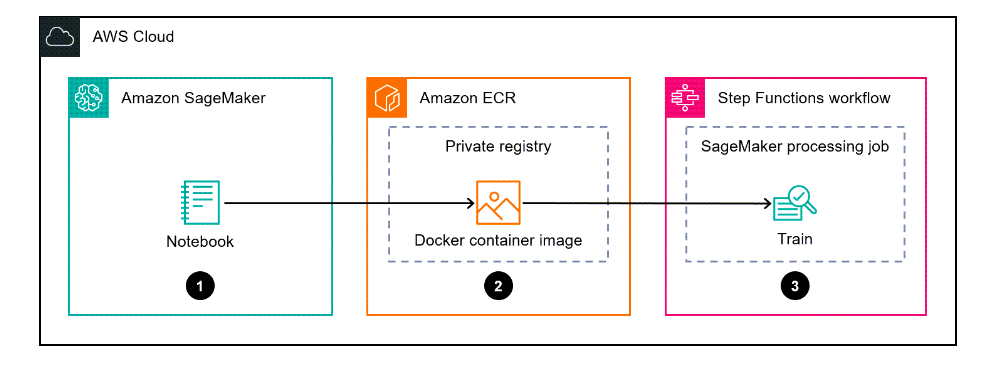
Architecture
The following diagram shows a workflow example for creating a Docker container image for SageMaker and using it for the training of a model in Step Functions.
The workflow includes the following steps.
- SageMaker notebook is used to create a custom Docker container image.
- The Docker container image is stored in Amazon ECR’s private repository.
- Docker container is used to run the Python SageMaker processing job.
Technology Stack
The Technology Stack includes:
- SageMaker
- Amazon ECR
- Step Functions
Tools
Following is the list of all the tools which will be required during the process.
- Amazon Elastic Container Registry
- Amazon SageMaker
- Amazon SageMaker Python SDK
- AWS Step Functions
- AWS Step Functions Data Science Python SDK
Creating a Custom Docker Container Image and Store it in Amazon ECR
Setup Amazon ECR and Create a New Private Repository.
- Set up the Amazon ECR by following proper instructions.
- Every AWS account is provided with a private ECR registry.
Create an Amazon ECR Private Repository
- ·Create a private ECR repository by following the step-by-step procedure.
- Create a Docker File.
- Create and configure the Dockerfile by including all the specifications needed to run your SageMaker processing job.
Code
Cell 1
# Make docker folder
!mkdir -p docker
Cell 2
%%writefile docker/Dockerfile
FROM python:3.7-slim-buster
RUN pip3 install pandas==0.25.3 scikit-learn==0.21.3
ENV PYTHONUNBUFFERED=TRUE
ENTRYPOINT ["python3"]Building and Pushing Docker Container Image to ECR
- Build the container image by running “docker build” command in the AWS CLI.
- Now push the container image to ECR using “docker push” command.
Code
Before running the following piece of code, make sure you have a well created Dockerfile which is stored in the docker directory. Moreover, Amazon ECR repository should also be created by you.
Cell 1
import boto3
tag = ':latest'
account_id = boto3.client('sts').get_caller_identity().get('Account')
region = boto3.Session().region_name
ecr_repository = 'byoc'
image_uri = '{}.dkr.ecr.{}.amazonaws.com/{}'.format(account_id, region, ecr_repository + tag)
Cell 2
# Build docker image
!docker build -t $image_uri docker
Cell 3
# Authenticate to ECR
!aws ecr get-login-password --region {region} | docker login --username AWS --password-stdin {account_id}.dkr.ecr.{region}.amazonaws.com
Cell 4
# Push docker image
!docker push $image_uriCreating a Step Function Workflow that Uses Custom Docker Container Image
Create a Python script that uses custom processing and model training logic.
- Write custom processing logic to run in data processing script. Save the script with the name training.py.
Code
%%writefile training.py
from numpy import empty
import pandas as pd
import os
from sklearn import datasets, svm
from joblib import dump, load
if __name__ == '__main__':
digits = datasets.load_digits()
#create classifier object
clf = svm.SVC(gamma=0.001, C=100.)
#fit the model
clf.fit(digits.data[:-1], digits.target[:-1])
#model output in binary format
output_path = os.path.join('/opt/ml/processing/model', "model.joblib")
dump(clf, output_path)Create a Step Functions Workflow that includes SageMaker Processing Job as one of its steps
First, you need to install and import AWS Step Functions Data Science SDK. After that, upload the training.py file to Amazon S3. Then use SageMaker Python SDK to define processing step in Step Functions.
Code
Example environment set up and custom training script to upload to Amazon S3
!pip install stepfunctions
import boto3
import stepfunctions
import sagemaker
import datetime
from stepfunctions import steps
from stepfunctions.inputs import ExecutionInput
from stepfunctions.steps import (
Chain
)
from stepfunctions.workflow import Workflow
from sagemaker.processing import ScriptProcessor, ProcessingInput, ProcessingOutput
sagemaker_session = sagemaker.Session()
bucket = sagemaker_session.default_bucket()
role = sagemaker.get_execution_role()
prefix = 'byoc-training-model'
# See prerequisites section to create this role
workflow_execution_role = f"arn:aws:iam::{account_id}:role/AmazonSageMaker-StepFunctionsWorkflowExecutionRole"
execution_input = ExecutionInput(
schema={
"PreprocessingJobName": str})
input_code = sagemaker_session.upload_data(
"training.py",
bucket=bucket,
key_prefix="preprocessing.py",
)
Example SageMaker processing step definition that uses a custom Amazon ECR image and Python script
script_processor = ScriptProcessor(command=['python3'],
image_uri=image_uri,
role=role,
instance_count=1,
instance_type='ml.m5.xlarge')
processing_step = steps.ProcessingStep(
"training-step",
processor=script_processor,
job_name=execution_input["PreprocessingJobName"],
inputs=[
ProcessingInput(
source=input_code,
destination="/opt/ml/processing/input/code",
input_name="code",
),
],
outputs=[
ProcessingOutput(
source='/opt/ml/processing/model',
destination="s3://{}/{}".format(bucket, prefix),
output_name='byoc-example')
],
container_entrypoint=["python3", "/opt/ml/processing/input/code/training.py"],
)
Example Step Functions workflow that runs a SageMaker processing job
workflow_graph = Chain([processing_step])
workflow = Workflow(
name="ProcessingWorkflow",
definition=workflow_graph,
role=workflow_execution_role
)
workflow.create()
# Execute workflow
execution = workflow.execute(
inputs={
"PreprocessingJobName": str(datetime.datetime.now().strftime("%Y%m%d%H%M-%SS")), # Each pre processing job (SageMaker processing job) requires a unique name,
}
)
execution_output = execution.get_output(wait=True)Conclusion
You can definitely use Docker with other services to make effective applications on your own. In this article, everything related to Docker and Dockerfile has been covered. It is encouraged to go ahead and experiment with the things which are mentioned in this article.