
.
Introduction
Retrieval-Augmented Generation (RAG) has revolutionized how Large Language Models (LLMs) interact with domain-specific or real-time information. By coupling an LLM with a retrieval mechanism that fetches relevant information from a knowledge base, RAG significantly mitigates issues like hallucination (generating factually incorrect information) and the inability to access current or proprietary data. This approach grounds LLM responses in verifiable sources, leading to more accurate and reliable outputs.
Despite its advantages, building effective RAG applications presents its own set of challenges. These include ensuring the retrieved information is highly relevant to the user’s query, guaranteeing the LLM’s generated response faithfully adheres to the retrieved context, and managing the continuous evolution of source data. Traditionally, evaluating RAG performance has been a manual, labor-intensive process, making iterative improvements difficult.
Amazon Bedrock Knowledge Base evaluation directly addresses these challenges by providing automated, built-in capabilities to assess the quality of RAG pipelines. This allows machine learning engineers, solution architects, and developers to quantitatively measure key aspects like relevance and faithfulness, enabling data-driven optimization of their Generative AI (GenAI) applications.
Understanding Amazon Bedrock Knowledge Bases
Amazon Bedrock Knowledge Bases serve as a fully managed solution that empowers Foundation Models (FMs) in Amazon Bedrock with access to your proprietary data. They act as a critical component in RAG architectures, providing the grounding context necessary for FMs to generate accurate and contextually relevant responses.
At its core, a Knowledge Base integrates with various data sources, including Amazon S3, and utilizes vector stores such as Amazon OpenSearch Service or Amazon Kendra to index and store your documents in a searchable format. When a user query is received, the Knowledge Base intelligently retrieves the most relevant document chunks based on semantic similarity, which are then passed to the chosen Foundation Model as context. This ensures that the FM’s response is informed by your specific data, reducing the likelihood of generating inaccurate or generic information.
The typical RAG workflow with Amazon Bedrock Knowledge Base integration can be visualized as follows:
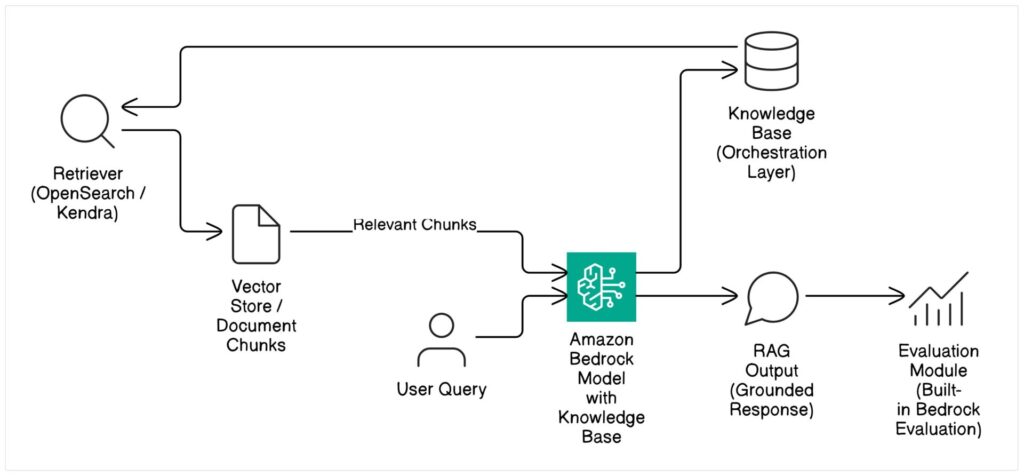
Architectural Diagram: RAG Workflow with Amazon Bedrock Knowledge Base
Built-in RAG Evaluation Capabilities
Amazon Bedrock’s RAG evaluation module provides a streamlined way to automatically assess the quality of your RAG pipeline. This built-in capability significantly reduces the manual effort traditionally associated with evaluating RAG applications, enabling faster iteration and improvement cycles.
The evaluation module focuses on two critical metrics for RAG quality:
- Faithfulness: This metric assesses whether the generated response is factually consistent with the retrieved source documents. A high faithfulness score indicates that the LLM is accurately synthesizing information from the provided context without introducing new, ungrounded facts or contradictions.
- Relevance: This metric measures how pertinent the generated response is to the user’s original query. It ensures that the LLM’s output directly addresses the user’s intent and doesn’t drift to irrelevant topics, even if grounded in the retrieved documents.
The Bedrock RAG evaluation supports both:
- Reference-based evaluations: In this approach, you provide a ground truth “expected response” for each query. The evaluation model compares the RAG output against this reference to determine faithfulness and relevance. This is ideal when you have a curated dataset of questions and their ideal answers.
- No-reference evaluations: For scenarios where ground truth responses are unavailable or impractical to generate, Bedrock can still perform evaluations. In this case, the evaluation model primarily assesses the faithfulness of the generated response to the retrieved documents and the relevance of the retrieved documents to the query, without comparing against a pre-defined “correct” answer.
Amazon Bedrock leverages powerful Foundation Models, such as Claude and Titan, as “evaluator models” to perform these assessments. These models are adept at understanding context, identifying factual consistency, and discerning relevance, making them ideal for automated RAG evaluation.
Setting Up RAG Evaluation in Bedrock
Setting up RAG evaluation in Amazon Bedrock involves a series of steps, from preparing your knowledge base to submitting the evaluation request.
1. Create and Configure a Knowledge Base
Before you can evaluate, you need a functional Knowledge Base.
import boto3
import json
bedrock_agent_client = boto3.client('bedrock-agent')
# Define S3 bucket for data source
s3_bucket_name = "your-rag-data-bucket"
data_source_name = "customer-faq-data"
# Create a Knowledge Base (if not already exists)
# Replace with your actual execution role ARN and vector store configuration
knowledge_base_name = "CustomerSupportKnowledgeBase"
knowledge_base_description = "Knowledge Base for customer support FAQs"
knowledge_base_execution_role_arn = "arn:aws:iam::123456789012:role/BedrockKnowledgeBaseRole" # Replace with your IAM Role
# Example Vector Store Configuration (OpenSearch Service)
# You would have already created an OpenSearch Service domain and collection
opensearch_vector_store_config = {
"vectorStoreType": "OPENSEARCH_SERVERLESS",
"opensearchServerlessConfiguration": {
"collectionArn": "arn:aws:aoss:us-east-1:123456789012:collection/your-opensearch-collection-id",
"vectorIndexName": "bedrock-knowledge-base-index",
"fieldMapping": {
"vectorField": "vector_embedding",
"textField": "text",
"metadataField": "metadata"
}
}
}
try:
response = bedrock_agent_client.create_knowledge_base(
name=knowledge_base_name,
description=knowledge_base_description,
roleArn=knowledge_base_execution_role_arn,
knowledgeBaseConfiguration={
"type": "VECTOR_DATABASE",
"vectorKnowledgeBaseConfiguration": opensearch_vector_store_config
}
)
knowledge_base_id = response['knowledgeBase']['knowledgeBaseId']
print(f"Knowledge Base '{knowledge_base_name}' created with ID: {knowledge_base_id}")
except bedrock_agent_client.exceptions.ConflictException:
print(f"Knowledge Base '{knowledge_base_name}' already exists.")
# Retrieve existing knowledge base ID if it already exists
response = bedrock_agent_client.list_knowledge_bases(
maxResults=100
)
for kb in response['knowledgeBaseSummaries']:
if kb['name'] == knowledge_base_name:
knowledge_base_id = kb['knowledgeBaseId']
print(f"Retrieved existing Knowledge Base ID: {knowledge_base_id}")
break
# Add a data source (if not already exists)
s3_data_source_config = {
"type": "S3",
"s3Configuration": {
"bucketArn": f"arn:aws:s3:::{s3_bucket_name}",
# "inclusionPrefixes": ["docs/"] # Optional: specify a prefix
}
}
try:
response = bedrock_agent_client.create_data_source(
name=data_source_name,
description="S3 data source for customer FAQs",
knowledgeBaseId=knowledge_base_id,
dataSourceConfiguration=s3_data_source_config
)
data_source_id = response['dataSource']['dataSourceId']
print(f"Data Source '{data_source_name}' created with ID: {data_source_id}")
except bedrock_agent_client.exceptions.ConflictException:
print(f"Data Source '{data_source_name}' already exists.")
# Retrieve existing data source ID
response = bedrock_agent_client.list_data_sources(
knowledgeBaseId=knowledge_base_id
)
for ds in response['dataSourceSummaries']:
if ds['name'] == data_source_name:
data_source_id = ds['dataSourceId']
print(f"Retrieved existing Data Source ID: {data_source_id}")
break
# Start an ingestion job to sync documents
print(f"Starting ingestion job for Data Source: {data_source_id} in Knowledge Base: {knowledge_base_id}")
response = bedrock_agent_client.start_ingestion_job(
knowledgeBaseId=knowledge_base_id,
dataSourceId=data_source_id
)
print("Ingestion job initiated. Monitor its status in Bedrock console.")
2. Upload Source Documents
Ensure your source documents are uploaded to the S3 bucket configured as the data source for your Knowledge Base. These documents will be chunked, embedded, and stored in your chosen vector database during the ingestion process.
3. Configure the Retriever
The retriever configuration is part of your Knowledge Base setup and dictates how documents are fetched from the vector store. This includes parameters like the number of results to retrieve and any filtering criteria. The evaluation process will implicitly use this configured retriever.
4. Create Evaluation Configuration
The evaluation configuration defines the parameters for your RAG evaluation, including the metrics to assess, the evaluation dataset, and the models to use.
{
"evaluationJobName": "CustomerSupportRAGEval-Run1",
"evaluationConfig": {
"bedrockModelEvaluationConfiguration": {
"outputDataConfig": {
"s3Uri": "s3://your-eval-output-bucket/rag-eval-results/",
"outputDatasetType": "JSON_L"
},
"taskType": "RAG"
}
},
"inferenceConfig": {
"bedrockInferenceConfiguration": {
"modelId": "arn:aws:bedrock:us-east-1::foundation-model/anthropic.claude-3-sonnet-20240229-v1:0" # Or other suitable FM
}
},
"customerKnowledgeBaseConfig": {
"knowledgeBaseId": "YOUR_KNOWLEDGE_BASE_ID", # Replace with your Knowledge Base ID
"retrieveAndGenerateConfiguration": {
"generationConfiguration": {
"promptTemplate": {
"text": "Answer the following question based on the provided context. If the answer is not in the context, state that you don't know.\n\nContext: {context}\n\nQuestion: {question}\n\nAnswer:"
}
}
}
},
"evaluationInputDataConfig": {
"s3Uri": "s3://your-eval-input-bucket/rag_evaluation_data.jsonl",
"inputDatasetType": "JSON_L"
}
}
Sample Evaluation Input Format (rag_evaluation_data.jsonl):
Each line in the .jsonl file represents a single evaluation entry.
{"query": "What is the return policy for electronics?", "expected_response": "Our return policy for electronics allows returns within 30 days of purchase, provided the item is in its original packaging and condition with proof of purchase. Some exclusions apply, please check our website for details."}
{"query": "How do I reset my password?", "expected_response": "To reset your password, visit the login page and click on 'Forgot Password'. Follow the instructions to receive a password reset link in your registered email."}
{"query": "Where can I find information about shipping costs?", "expected_response": "Shipping costs are calculated based on your location and the weight of your order. You can view the estimated shipping cost during checkout before finalizing your purchase."}
{"query": "Is there a loyalty program?", "expected_response": "Yes, we offer a customer loyalty program. You can sign up on our website to earn points on every purchase, redeemable for discounts and exclusive offers."}
{"query": "What are your business hours?", "expected_response": "Our customer support is available Monday to Friday, 9 AM to 5 PM EST. Our online store is open 24/7."}
For no-reference evaluation, the expected_response field can be omitted or left blank.
5. Submit RAG Evaluation Request
Use the boto3 client to submit the evaluation job.
import boto3
import json
bedrock_client = boto3.client('bedrock')
evaluation_job_name = "CustomerSupportRAGEval-Run1"
knowledge_base_id = "YOUR_KNOWLEDGE_BASE_ID" # Replace with your Knowledge Base ID
input_data_s3_uri = "s3://your-eval-input-bucket/rag_evaluation_data.jsonl"
output_data_s3_uri = "s3://your-eval-output-bucket/rag-eval-results/"
inference_model_id = "arn:aws:bedrock:us-east-1::foundation-model/anthropic.claude-3-sonnet-20240229-v1:0" # Or other suitable FM
evaluation_config = {
"evaluationJobName": evaluation_job_name,
"evaluationConfig": {
"bedrockModelEvaluationConfiguration": {
"outputDataConfig": {
"s3Uri": output_data_s3_uri,
"outputDatasetType": "JSON_L"
},
"taskType": "RAG"
}
},
"inferenceConfig": {
"bedrockInferenceConfiguration": {
"modelId": inference_model_id
}
},
"customerKnowledgeBaseConfig": {
"knowledgeBaseId": knowledge_base_id,
"retrieveAndGenerateConfiguration": {
"generationConfiguration": {
"promptTemplate": {
"text": "Answer the following question based on the provided context. If the answer is not in the context, state that you don't know.\n\nContext: {context}\n\nQuestion: {question}\n\nAnswer:"
}
}
}
},
"evaluationInputDataConfig": {
"s3Uri": input_data_s3_uri,
"inputDatasetType": "JSON_L"
},
"roleArn": "arn:aws:iam::123456789012:role/BedrockEvaluationRole" # IAM role for evaluation job
}
try:
response = bedrock_client.create_model_evaluation_job(
jobName=evaluation_config['evaluationJobName'],
roleArn=evaluation_config['roleArn'],
inputDataConfig=evaluation_config['evaluationInputDataConfig'],
outputDataConfig=evaluation_config['evaluationConfig']['bedrockModelEvaluationConfiguration']['outputDataConfig'],
evaluationConfig=evaluation_config['evaluationConfig']['bedrockModelEvaluationConfiguration'],
inferenceConfig=evaluation_config['inferenceConfig']['bedrockInferenceConfiguration'],
customerKnowledgeBaseConfig=evaluation_config['customerKnowledgeBaseConfig']
)
print(f"Evaluation job '{evaluation_job_name}' submitted successfully.")
print(f"Job ARN: {response['jobArn']}")
print(f"Job Status: {response['status']}")
except Exception as e:
print(f"Error submitting evaluation job: {e}")
Interpreting Evaluation Results
Once the evaluation job completes, the results will be deposited in the specified S3 output location as a .jsonl file. Each line in this file corresponds to an evaluated input from your dataset.
Sample Evaluation Output Structure (each line in output.jsonl):
{
"input": {
"query": "What is the return policy for electronics?",
"expected_response": "Our return policy for electronics allows returns within 30 days of purchase, provided the item is in its original packaging and condition with proof of purchase. Some exclusions apply, please check our website for details."
},
"output": {
"retrieved_documents": [
{"text": "Returns for electronics are accepted within 30 days. Item must be in original condition and packaging. Proof of purchase required."},
{"text": "For full details on returns, visit our website's FAQ section. Some items are non-returnable."}
],
"generated_response": "For electronics, you can return items within 30 days of purchase if they are in their original packaging and condition with proof of purchase. Certain exclusions may apply."
},
"metrics": {
"faithfulness": {
"score": 0.95,
"explanation": "The generated response accurately reflects the information found in the retrieved documents regarding the return policy for electronics."
},
"relevance": {
"score": 0.98,
"explanation": "The generated response directly answers the query about the return policy for electronics and is highly relevant."
}
},
"status": "COMPLETED"
}
Key elements in the output include:
input: The original query and theexpected_response(if provided in the input dataset).output: Containsretrieved_documents(the text chunks fetched by the Knowledge Base) and thegenerated_response(the LLM’s answer based on the retrieved documents).metrics: This is the core of the evaluation.faithfulness: A score (typically between 0 and 1) indicating how well thegenerated_responseis supported by theretrieved_documents. A higher score means less hallucination. Theexplanationprovides human-readable reasoning from the evaluation model.relevance: A score (typically between 0 and 1) indicating how well thegenerated_responseaddresses thequery. A higher score means the answer is more on-topic. Theexplanationelaborates on the relevance assessment.
status: Indicates the status of that specific evaluation entry (e.g.,COMPLETED).
Visualizing Trends:
To gain actionable insights, you can:
- Aggregate Scores: Calculate average faithfulness and relevance scores across your entire dataset or for specific subsets of queries.
- Filter by Low Scores: Identify queries or document retrievals that resulted in low faithfulness or relevance scores. These are prime candidates for investigation and improvement.
- Trend Analysis: Run evaluations iteratively as you refine your prompt engineering, chunking strategy, or retriever configuration. Store the results in Amazon S3 and use services like Amazon Athena to query the
jsonlfiles and Amazon QuickSight to visualize trends over time. This helps you understand if your changes are positively impacting RAG quality.
Use Case Example: Customer Support Chatbot
Consider a customer support chatbot that uses a RAG pipeline powered by an Amazon Bedrock Knowledge Base to answer customer inquiries based on a company’s FAQ and policy documents.
Goal: Ensure the chatbot provides accurate and relevant answers, minimizing hallucinations and irrelevant information.
Let’s walk through some evaluation scenarios:
Scenario 1: Correct Answer Grounded in Documents
- Query: “What is your refund policy?”
- Retrieved Documents (hypothetical):
- “Our standard refund policy allows returns within 30 days for a full refund, provided the item is unused and in original packaging. For digital goods, refunds are only issued if the download has not occurred.”
- “Refunds are processed within 5-7 business days after the returned item is received and inspected.”
- Generated Response: “Our refund policy states that you can get a full refund within 30 days if the item is unused and in its original packaging. Digital good refunds are only applicable if not downloaded. Refunds are processed in 5-7 business days.”
- Evaluation Output:
faithfulness: ~0.98 (Explanation: “The response accurately summarizes the refund policy details found in the provided documents.”)relevance: ~0.99 (Explanation: “The response directly addresses the query about the refund policy.”)
Scenario 2: Partial Hallucination
- Query: “Can I return a used item for a full refund?”
- Retrieved Documents (hypothetical):
- “Our standard refund policy allows returns within 30 days for a full refund, provided the item is unused and in original packaging.”
- Generated Response: “Yes, you can return a used item for a full refund within 30 days, as long as you have the original packaging.” (INCORRECT – contradicts “unused”)
- Evaluation Output:
faithfulness: ~0.40 (Explanation: “The response incorrectly states that used items can be returned for a full refund, which contradicts the ‘unused’ requirement in the document.”)relevance: ~0.90 (Explanation: “The response attempts to address the query about returns but contains factual inaccuracies.”)
This low faithfulness score immediately flags a critical issue. The development team can investigate the prompt, chunking strategy, or even the LLM’s temperature settings to prevent such contradictions.
Scenario 3: Irrelevant Retrieval Leading to “I don’t know”
- Query: “What is the capital of France?” (Out of scope for a customer support KB)
- Retrieved Documents (hypothetical): (Empty or highly irrelevant documents like “Our office is located in Paris, France.”)
- Generated Response: “I am sorry, but I do not have information on the capital of France. My knowledge is limited to customer support topics.”
- Evaluation Output:
faithfulness: ~0.95 (Explanation: “The response correctly states it doesn’t know, which is consistent with the lack of relevant information in the provided context.”)relevance: ~0.10 (Explanation: “The retrieved documents are irrelevant to the user’s query, although the model’s response is appropriate given the lack of context.”)
While the faithfulness is high (the model correctly states it doesn’t know), the low relevance score signals that the retriever either failed to find relevant information or, more likely in this case, the query is out of the Knowledge Base’s domain. This could indicate a need for better query filtering or a more robust “no answer” strategy at the application level.
By regularly running these evaluations, the team can identify and prioritize areas for improvement. For instance, a consistently low faithfulness score might indicate issues with the prompt’s instructions to the LLM (e.g., “be factual,” “only use provided context”), while low relevance could point to an inefficient retriever or poorly chunked documents.
Best Practices for RAG Evaluation
Integrating RAG evaluation into your development lifecycle is crucial for maintaining high-quality GenAI applications.
- Run Evaluations Iteratively During Tuning: As you experiment with different prompt engineering techniques, LLM models, chunking strategies, or retriever configurations (e.g., changing
max_tokens,temperature,top_k), run evaluation jobs to quantitatively measure the impact of your changes. This iterative approach allows for data-driven optimization. - Use Evaluations as Part of CI/CD Pipeline for GenAI: Automate RAG evaluations as a gate in your continuous integration/continuous delivery (CI/CD) pipeline. Before deploying a new version of your RAG application or updating your Knowledge Base, run a suite of evaluation tests. If key metrics (e.g., average faithfulness or relevance) fall below a predefined threshold, the deployment can be blocked, preventing regressions in performance.
- Store Results in S3 and Analyze with Athena/QuickSight: All evaluation outputs are stored in Amazon S3. Leverage services like Amazon Athena to query these
.jsonlfiles using standard SQL. For visual analysis and dashboarding, integrate with Amazon QuickSight. This allows you to track performance trends over time, identify problem areas, and generate reports for stakeholders. - Integrate with Human Feedback (RHF) Workflows: While automated evaluations are powerful, they cannot replace human judgment entirely. Use the automated evaluations to identify edge cases or instances where the model performed poorly. Integrate these flagged instances into a human-in-the-loop (HIL) process. Tools like Amazon SageMaker Ground Truth can be used to set up annotation jobs where human reviewers provide feedback on the accuracy and relevance of responses, enriching your evaluation dataset for future runs or fine-tuning.
Conclusion
Amazon Bedrock’s native RAG evaluation capabilities provide an indispensable tool for developers building robust and reliable Generative AI applications. By offering automated assessments of faithfulness and relevance, Bedrock simplifies the complex task of optimizing RAG pipelines. This allows you to move beyond qualitative assessments and embrace a data-driven approach to improving your LLM-powered applications.
Integrating RAG evaluation early and continuously throughout the development lifecycle empowers you to detect and rectify issues proactively, ensuring your RAG applications consistently deliver accurate, grounded, and relevant information to your users. As the GenAI landscape evolves, we can anticipate further enhancements to these evaluation capabilities, potentially including support for custom metrics, multi-lingual evaluation, and more sophisticated few-shot evaluators, further solidifying Bedrock’s position as a comprehensive platform for GenAI development. Embracing these evaluation mechanisms is not just a best practice; it’s a fundamental requirement for building high-performing and trustworthy RAG solutions on AWS.
A Software Engineer by profession and a Writer by passion