
AWS Glue is a fully managed extract, transform, and load (ETL) service that makes it easy for customers to prepare and load their data for analytics.
AWS Glue can read, write, and process data stored in Amazon S3, Amazon DynamoDB, Amazon Aurora, relational databases such as Amazon Redshift, Apache Hive metastore databases such as Apache Hive or Apache Hadoop Distributed File System (HDFS), and even your on-premises data stores.
With AWS Glue; you pay only for the time you use the service. There are no upfront commitments or minimum fees.
How AWS Glue Works:
AWS Glue automatically discovers and profiles your data via the Glue Data Catalogue. The Data Catalogue is a central metadata repository that is used to store and maintain information about all the data assets of an organisation.
Data Catalogue
The Data Catalogue contains references to data that is used as sources and targets by AWS Glue ETL jobs and development endpoints. It also stores the structure and schema of your data.
As new data is added to your data stores ⇒ AWS Glue can automatically detect and catalogue it.
To prepare your data for analytics; you can use AWS Glue to transform it into a format that is optimised for analysis.
With AWS Glue, you can convert your data into columnar Parquet or Apache ORC formats, which are optimised for Amazon Athena, Amazon Redshift Spectrum, and Amazon EMR.
TIP: You can also compress your data with Gzip or Snappy to reduce storage costs.
How to load data into data stores:
To load your data into Amazon Redshift, Amazon DynamoDB, Amazon Aurora, or other data stores, you can use AWS Glue to run an ETL job. An ETL job reads data from your source data store, transforms it according to your specifications, and writes the transformed data to your target data store.
You can also use AWS Glue jobs to prepare and load your data for analytics tools such as Amazon Athena, Amazon EMR, and Amazon Redshift Spectrum.
AWS Glue + AWS Lambda
AWS Lambda is a serverless compute service that lets you run code without provisioning or managing servers. AWS Lambda executes your code ONLY when needed and scales automatically, from a few requests per day to thousands per second.
You pay only for the compute time you consume – there is no charge when your code is not running. With Lambda, you can run code for virtually any type of application or backend service – all with zero administration.
AWS Lambda runs your code on a high-availability compute infrastructure and performs all of the administration of the compute resources, including server and operating system maintenance, capacity provisioning, and automatic scaling. All you need to do is supply your code in the form of one or more Lambda functions.
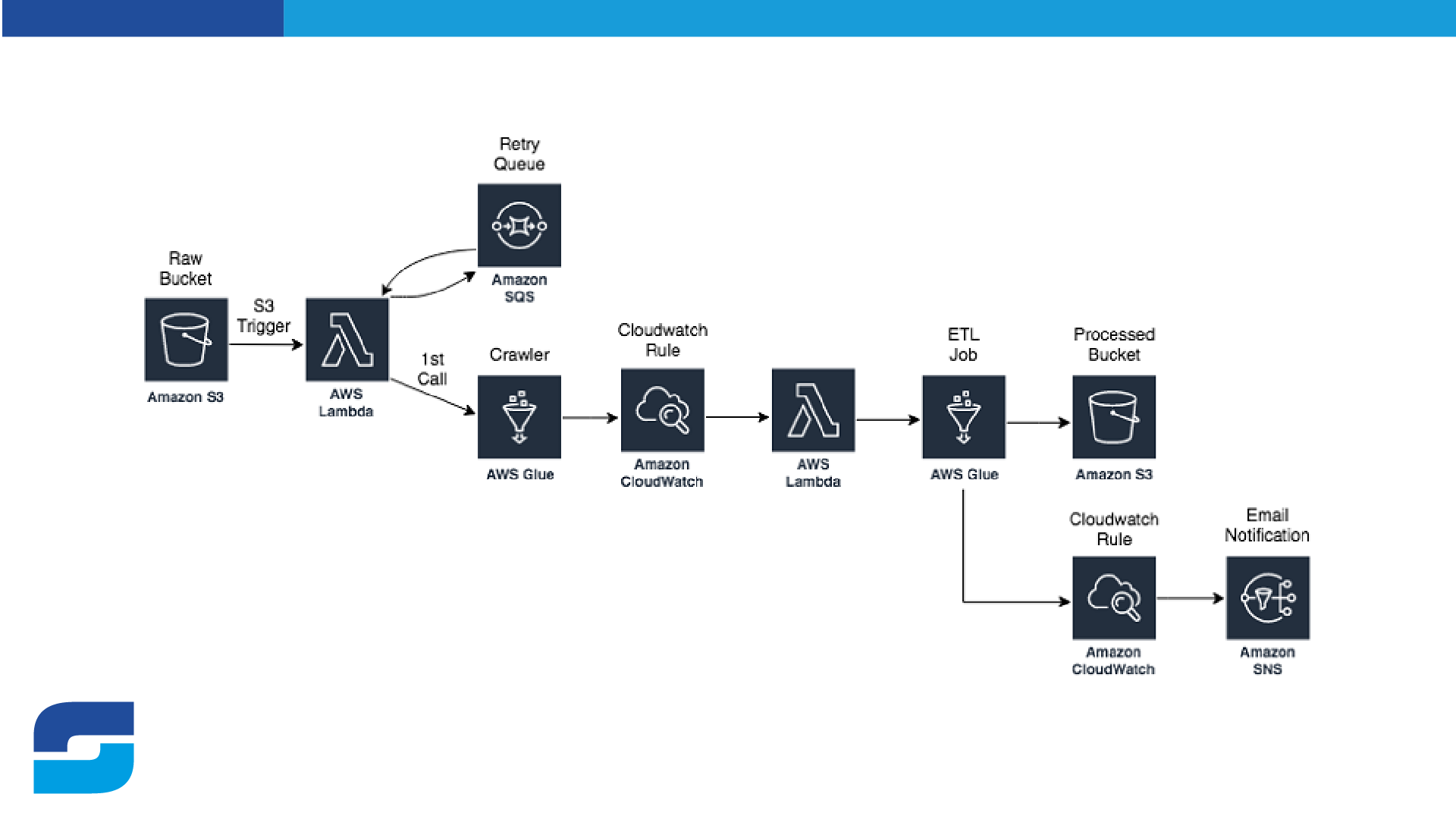
You can use AWS Glue and AWS Lambda together to build serverless ETL applications.
AWS Glue is integrated with AWS Lambda so that you can easily build serverless ETL jobs. With Lambda integration, you can invoke a Lambda function to perform custom transformations on your data before it is loaded into your data store.
For example,
- you can use a Lambda function to convert your data from CSV to Apache Parquet format before it is loaded into Amazon S3.
- you can use a Lambda function to perform custom transformations on your data before it is loaded into your data store.
- you can use Lambda to trigger an ETL job in response to events in other AWS services such as Amazon S3 or Amazon DynamoDB.
AWS Glue also provides a flexible scheduling mechanism that can be used to run ETL jobs on a recurring basis. You can schedule jobs to run hourly, daily, weekly, or on any other frequency that you choose.
AWS Glue can even trigger jobs based on events in other AWS services such as Amazon S3 or Amazon DynamoDB.
Monitoring
To monitor the progress of your ETL jobs, you can use the AWS Glue console or the AWS Command Line Interface (CLI). The AWS Glue console shows the status of all your ETL jobs in one place. You can also use the AWS Glue CLI to monitor job progress.
AWS Glue is a fully managed service that you can use at no additional charge. There are no upfront commitments or minimum fees. You only pay for the resources that your ETL jobs consume.
To get started, simply create an AWS Glue Data Catalogue and then use it to run ETL jobs.
Conclusion
AWS Glue is a powerful tool that can help you automate the data ingestion process and improve your data analysis workflows. With its easy-to-use graphical interface and support for multiple programming languages, AWS Glue makes it simple to get your data into shape so you can start analyzing it. If you’re looking for a more efficient way to ingest your data or want to start taking advantage of machine learning algorithms to gain insights from your data, give AWS Glue a try.