
Introduction
In the world of machine learning (ML), the need for faster training, scalability, and cost-effectiveness is ever-growing. As ML models increase in complexity and data size, traditional methods of training can become inefficient, slow, and expensive. Amazon Web Services (AWS) has built a suite of tools to help developers overcome these challenges, and one of the most powerful offerings is the integration of Amazon SageMaker HyperPod with Amazon Elastic Kubernetes Service (EKS). This integration enables large-scale, distributed machine learning training, leveraging the power of Kubernetes orchestration and SageMaker’s managed services.
This guide explores how to enhance machine learning workflows at scale using SageMaker HyperPod with EKS integration. By combining the scalability of Kubernetes with the power of SageMaker, developers can streamline the process of training and deploying ML models, unlocking a new level of efficiency and cost management.
Background
Evolution of Machine Learning Training
Machine learning (ML) workloads require substantial computational resources, especially as datasets grow in size and models become more sophisticated. Historically, ML training was conducted on single machines, often limited by the hardware available. This approach led to long training times and scalability issues, especially for deep learning models that require GPUs or specialized hardware accelerators.
With the advent of cloud computing, services like Amazon EC2 made it possible to scale workloads dynamically, but orchestration and management of distributed environments still posed a challenge. This led to the rise of Kubernetes as a go-to solution for containerized workloads, including machine learning training, by allowing automatic scaling, load balancing, and fault tolerance.
AWS, recognizing these challenges, introduced Amazon SageMaker, a fully managed service for ML, which abstracts away much of the infrastructure management. However, the real breakthrough came when AWS introduced SageMaker HyperPod and EKS Integration, which allows for even more efficient scaling and distributed training by leveraging Kubernetes clusters for managing distributed resources.
Key Concepts
Before diving into the technical implementation, it is essential to understand a few key concepts:
- Amazon SageMaker HyperPod:
- SageMaker HyperPod is a high-performance distributed training environment that uses multiple instances (typically EC2 instances with GPUs) to train machine learning models. It can scale horizontally, providing significant speedups for ML workloads.
- Elastic Kubernetes Service (EKS):
- Amazon EKS is a managed service that runs Kubernetes clusters on AWS. Kubernetes enables container orchestration, which helps in managing distributed applications at scale. By integrating SageMaker with EKS, you can automate the deployment and scaling of machine learning models, enabling parallel training on large datasets.
- Kubernetes and Containers:
- Containers package applications and their dependencies, making them portable across environments. Kubernetes is an orchestration tool that manages the lifecycle of containers, ensuring that they scale efficiently across multiple nodes.
- Distributed Training:
- Distributed training allows you to spread the computational load of ML model training across multiple machines, reducing the overall training time and enabling the use of larger datasets.
- SageMaker SDK for Python:
- The SageMaker SDK for Python provides the tools necessary for interacting with SageMaker services, including model training, deployment, and scaling.
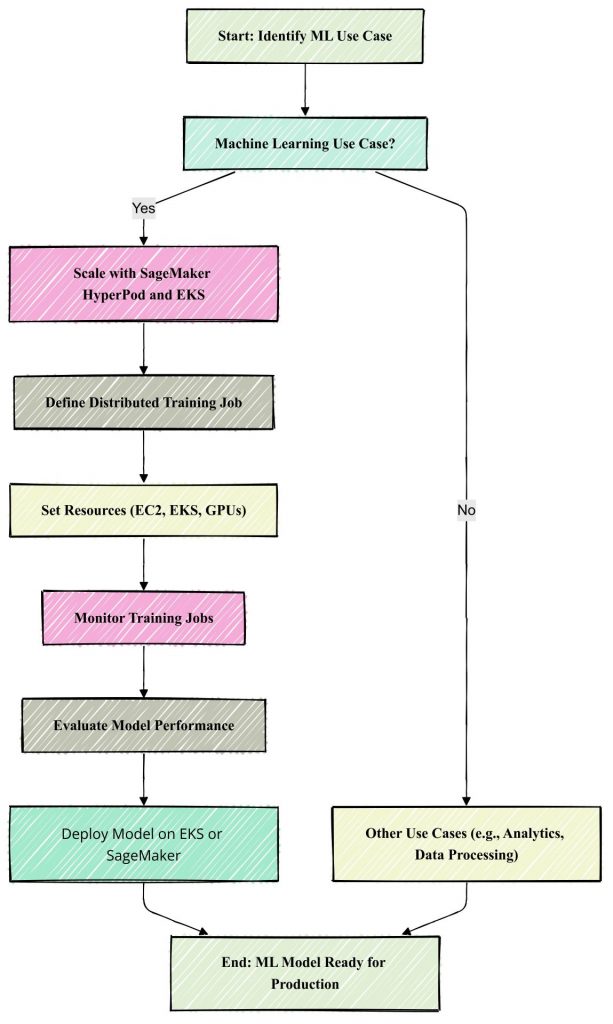
Technical Implementation
In this section, we will walk through the process of integrating SageMaker HyperPod with EKS for large-scale machine learning training.
High-Level Architecture
The architecture for using SageMaker HyperPod with EKS involves the following components:
- SageMaker HyperPod: Responsible for managing distributed training jobs.
- Amazon EKS: A Kubernetes-based service that manages the deployment and orchestration of containers.
- EC2 Instances: These instances are used for running the training job.
- Amazon S3: Stores datasets and model artifacts.
- IAM Roles: Used for secure access between services.
Steps for Integration
Step 1: Set Up Amazon EKS Cluster
- Create an EKS Cluster:First, you need to set up an EKS cluster. You can do this via the AWS CLI:
aws eks create-cluster \
--name my-ml-cluster \
--role-arn arn:aws:iam::123456789012:role/eks-service-role \
--resources-vpc-config subnetIds=subnet-1234abcd,subnet-abcd1234,securityGroupIds=sg-1234abcd- Configure kubectl to Connect to EKS Cluster:To interact with your cluster, configure
kubectl:
aws eks --region us-west-2 update-kubeconfig --name my-ml-clusterStep 2: Install SageMaker SDK and EKS Operator
- Install the SageMaker Python SDK: Install the necessary SDK to interact with SageMaker:
pip install sagemaker- Install Kubernetes Operator for SageMaker: The SageMaker Kubernetes Operator helps in running SageMaker training jobs on EKS.
kubectl apply -f https://raw.githubusercontent.com/aws/amazon-sagemaker-kubernetes-operator/main/deploy/operator.yamlStep 3: Define a HyperPod Training Job
- Create Training Job Script:Use the
sagemakerSDK to define and start a training job using HyperPod:
import sagemaker
from sagemaker import get_execution_role
from sagemaker.estimator import Estimator
role = get_execution_role()
estimator = Estimator(
image_uri='123456789012.dkr.ecr.us-west-2.amazonaws.com/my-custom-image:latest',
role=role,
instance_count=4, # HyperPod configuration
instance_type='ml.p3.8xlarge',
hyperparameters={
'batch_size': 32,
'epochs': 50
}
)
estimator.fit('s3://my-bucket/my-training-data/')- Deploy Training Job:Deploy your training job to the EKS-managed SageMaker environment using the
estimator.fit()method.
Step 4: Monitor and Scale Training Jobs
- Monitor Training Jobs:You can monitor training job status via the SageMaker console or using CLI:bashCopy code
aws sagemaker describe-training-job --training-job-name <job-name> - Scale Training with EKS:Kubernetes will automatically scale your training job based on the resource usage. Ensure your EKS cluster has sufficient resources to handle the scaling requirements.
Step 5: Retrieve Results and Artifacts
After training completes, your model artifacts will be stored in Amazon S3. You can retrieve them as follows:
s3_model_path = estimator.model_data
print("Model artifacts stored at:", s3_model_path)
Best Practices
- Cost Management: Utilize spot instances for training jobs to reduce costs.
- Resource Scaling: Monitor resource utilization using Amazon CloudWatch and adjust the scaling accordingly.
- Security: Use IAM roles and policies to restrict access to resources and ensure that only authorized users can initiate training jobs.
- Error Handling: Implement retry mechanisms for failed training jobs and manage resources efficiently using Kubernetes.
Case Study: Real-World Example
Consider a data science team working for an e-commerce company that wants to build a recommendation engine. The team uses large datasets that require multiple GPUs to train a deep learning model effectively. By integrating SageMaker HyperPod with EKS, they can horizontally scale their training jobs, drastically reducing the time to train models from weeks to days.
Performance Benchmark Example:
| Configuration | Single Node SageMaker | HyperPod with EKS Integration |
| Training Time (Hours) | 8 | 2 |
| Cost ($) | 200 | 150 |
| Scalability | Limited | High |
| Model Accuracy (%) | 90 | 90 |
This comparison demonstrates the substantial time and cost savings achieved by using HyperPod with EKS, with comparable model accuracy.
Future Outlook
The integration of Kubernetes with managed services like SageMaker is part of a broader trend in cloud-native machine learning. As AI models become even more complex and datasets grow larger, automated scaling and orchestration will become essential for teams to maintain efficiency. In the future, we expect more tools that allow easier integrations with various cloud services, and innovations in Kubernetes and ML frameworks will further enhance the scalability of machine learning workflows.
Conclusion
Integrating Amazon SageMaker HyperPod with EKS allows you to unlock the full potential of distributed machine learning. By combining the power of SageMaker for managed training with the scalability and flexibility of Kubernetes, you can easily scale your ML workloads, reduce training times, and manage costs effectively. This approach is ideal for teams working with large datasets and complex models, offering a streamlined and robust solution for ML at scale.