
You might have heard about FinServ – Financial Service Industry. The FinServ industry has different and unique generative AI requirements. These requirements work well with domain specific data, like for data security, industry compliance standards and regulatory controls. Many customers are trying to figure out the best ML model that could fit into their business use cases. Remember that not every ML model is desirable, you have to mould it according to your needs and requirements with the help of fine-tuning.
As far as FinServ is concerned, Amazon SageMaker JumpStart is the most appropriate pick for the generative AI use cases. Why? Well, it fulfils all the necessary data requirements of FinServ. Apart from this all, we will be discussing RAG (Retrieval Augmented Generation) and its usage with LLMs in SageMaker JumpStart.
What is SageMaker?
SageMaker is an AWS service that makes use of a set of tools to enable low-cost and high performing machine learning use cases. It is used for building, training and deploying ML models at scale using various tools like debuggers, MLOps, pipelines, profilers etc.
Using SageMaker JumpStart, the ML practitioners can choose models for use cases like
- Content writing
- Image generation
- Code generation
- Copywriting
- Question answering
- Summarization
- Classification
- Retrieving information
The flow goes like this; ML practitioners have foundation models, they deploy these models to the SageMaker instances (specifically from a network isolated environment) and then perform customization on the models for training and deployment.
Advantages of SageMaker
You will get the following advantages by using the Amazon SageMaker.
More Customization Control
SageMaker makes sure that the people don’t find any difficulty while following the procedure. So it provides example notebooks and a daily post for step-by-step guidance regarding domain adaptation of foundation models. These resources can be used for fine-tuning or to build RAG-applications.
More Data Security
SageMaker ensures the data security by deploying models in network isolation providing a single-tenancy endpoint. Also you can ensure the individual security requirements by managing control access through a private model hub capability.
Controls and Compliances
If we were to talk about the core feature of Sage Maker then it would be the compliance with standards like HIPAA BAA, SOC123, and PCI etc. It ensures the alignment with the regulatory landscape specifically of the financial sector.
Broad model choices
With SageMaker you will have the option to choose models that rank at the top. Some of such models are:
- Llama 2
- Falcon 40B
- Al21 J2 Ultra
- AI21 Summarize
Role in Chatbot Development
Well, in chatbot development the SageMaker Jumpstart plays a very important role. Some of the features include:
Accelerated Model Training
SageMaker provides pre-trained models so that the developers don’t waste their time on training the model for the chatbot development.
Access to Industry Practices
Developers can take advantage from the ML practitioners who have contributed broadly in the pre-built models.
Reduced Complexity
Due to the presence of pre-built models, the chatbot development process has been simplified. The developers can now focus on the integration part rather than the training part.
End-to-End Solutions
SageMaker provides end-to-end solutions for machine learning model deployment, development and management.
Llama 2 – Overview and Key Features
Llama 2 is a tool as well as a platform that assists data scientists and developers to build and deploy AI solutions. It provides advanced capabilities and features to streamline the process of chatbot development. Despite its older version, this version offers everything twice in terms of scalability, flexibility and efficiency. These all features make Llama 2 a valuable tool for creating chatbot interactions.
How Llama 2 Enhances Chatbot Interactions?
There are many features included in Llama 2 which enhance the chatbot interactions.
Better Understanding of User Intent
Llama 2 uses advanced NLP capabilities which help in understanding the user query better than before.
Contextual Responses
It also enables chatbot to maintain context in multiple turns
Multi Modal Interactions
Llama 2 enables multi-modal interactions that actually allows a chatbot to generate a response to a text, visual inputs and speech combination.
Amazon OpenSearch Server less
Amazon offers an OpenSearch Service, to have its on-demand server less configuration we use Amazon OpenSearch Server less. All the complexities associated with OpenSearch clusters will be removed by using server less. The operational complexities include provisioning, tuning and configuring the OpenSearch clusters.
Vector Engine
The vector engine as clear from its name is a simple vector storage for Amazon OpenSearch server less that provides search capability to the developers to build various AI and ML models without managing the vector database.
Advantages for Search and Analysis
Following are the search and analysis advantages that you will get by using a vector engine.
- Faster Similarity Search
- Efficient and convenient handling of high-dimensional data
- More Personalization Control
- Parallel Processing
- Real Time Analytics
- Enhancements in machine learning models
- Data Representation Flexibility
What is RAG?
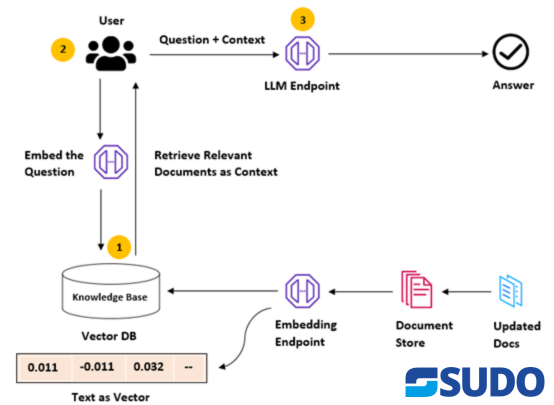
The full abbreviation of RAG is Retrieval Augmented Generation. It is typically a framework whose job is to improve the text generation quality. It does this by combining an Information Retrieval System with a Large Language Model. Another important component, knowledge base is used by the IR system and the LLM generated text to retrieve the relevant data. Once the information is successfully retrieved, the LLM’s input is augmented which in return improves the accuracy of the model generated text.
Advantages
RAG has the following advantages.
- Used to perform text generation tasks
- Used to perform the summarization of the question answers
- It improves the quality of text generation models
RAG WorkFlow
RAG operates in the following manner:
Data Sources
RAG collects information from various data sources which includes documents or APIs etc.
Data Formatting
The data fetched from documents and the user query both are converted into a common format to perform a comparison.
Embedding
All the data is converted into their relevant numerical representation known as embedding.
Search
The relevant embedding of user query and the embedding of document’s collection are compared to run a similarity search.
Context Enhancement
The context is enhanced by joining the relevant text with the user’s original prompt.
LLM Processing
Now the resultant context is provided as an input to the LLM which in return produces precise output.
The diagram below depicts the proper work flow of RAG.
Requirements
Use SageMaker JumpStart GPT-J-6B embedding model. It will be used to generate relevant embedding for PDF documents in the Amazon S3 upload directory.
- To identify the relevant document, perform the following steps.
- Use the above mentioned model to generate the embedding for user’s query
- Now use OpenSearch Server less (with the vector engine feature) to search for the top most relevant document indexes
- Retrieve the required document
- Combine the user’s prompt with the retrieved document and pass it to the SageMaker in order for it to generate response
Prerequisites
Following prerequisites will be needed to build a contextual chatbot.
- AWS Account with proper IAM permissions i.e. IAM Identity and Access Management
- Setup your Amazon SageMaker Studio for accessing domain and user by following the proper instructions
- Amazon OpenSearch Server less collection
- SageMaker execution role having access to OpenSearch Server less
Building the Chatbot
Here is the complete github code for your chatbot ,where you just have to make changes as per your aws credentials and region.
You can directly import this link in AWS Sagemaker to make changes to the file accordingly or you can download the github file and upload in jupyter notebook of sagemaker.
You can chose the python kernel or sage-maker distribution python based on your preferences
Integration and Deployment using AWS
Following AWS services are required for the integration and deployment of chatbot.
SageMaker – For building, training and deploying ML models
Amazon S3 – For storing documents, datasets and scalable object
OpenSearch Service – Managed service for elastic search
Amazon API Gateway – For creating, deploying and managing APIs
AWS Lambda – For running code without managing servers
AWS Identity and Access Management – For a secure access control to AWS resources
It is really important to keep a check and balance on the chatbot once it has been deployed. Real-time monitoring can help a lot in this cause. It will provide an immediate bug report so we can fix it as soon as we are told.
Security and Compliance
You can ensure data security and privacy through encryption, by adjusting the access controls, conducting regular security audits and using data masking techniques. All these things will definitely lead to a more secure environment.
Conclusion
In a nutshell, we learned how to build a contextual chatbot using the RAG approach. It was used to provide domain specific content to LLMs. Then we used a bunch of advanced services and tools like vector DB, SageMaker and OpenSearch server less etc. to create an enhanced version of it. This will allow users to bring custom data and not only the domain specific data.
A Software Engineer by profession and a Writer by passion