How to grow your business with Data Mesh and Data Lake on AWS
What is Data Mesh?
We define a data mesh as an infrastructure allowing different data consumers to share, consume, and collaborate on the same data without directly accessing or storing it. A data mesh consists of two primary components: a data discovery service and a database service.
In the past, companies acquire different systems to collect customer information. Still, in the last few years, some firms have adopted a single approach to collect all types of customer information, regardless of channel. What do you call this system? Data mesh. Data mesh is a software architecture that collects and stores any customer information you want—online, in-store, in call centers, and more—and allows you to merge this data into a single view that you can use across your company.
This blog describes how data mesh enables autonomous data operations while providing governance and security. We will also describe the architectural pattern of a data mesh and present a sample application that demonstrates the approach.
Data Mesh on AWS
AWS Data Mesh enables organizations of all sizes to build modern, secure data pipelines that scale as needed, from on-premises data to public clouds, to meet the diverse needs of their organizations and customers.
In the era of the cloud computing revolution, data is everywhere. From email to social media, smartphones, and countless mobile devices, information is being generated and consumed at an unprecedented rate. With so much data flying through so many hands, you can’t afford to be without the right tools to help you make sense of all this information. Amazon Web Services (AWS) Data Mesh, the latest addition to Amazon’s data processing infrastructure, makes it easier than ever to store, process, and analyze your massive amounts of unstructured data. By using AWS Data Mesh, you can quickly ingest, transform and move large volumes of data between any two AWS services – and do it with ease.
In an era where all organizations are moving to cloud technology, there is now a need for Data-Driven Organizations (DDOs). An example of a DDO would be an organization that can utilize data from multiple AWS accounts to create a single consolidated view of its data.
Benefits of a data mesh model
Data meshes provide an efficient method for connecting and scaling data across different platforms. A data mesh allows data from different sources, such as databases and file systems, to be stored in a central location for retrieval and processing. The benefits of a data mesh include fast access to data, low storage costs, and more accessible data scaling as new sources are added.
The design process aims to build a framework that facilitates the creation of a sustainable model for the production, consumption, and curation of data. In particular, the design needs to support the goals of the following:
- Enable rapid experimentation with data-related applications and processes.
- Enable the creation of new data-oriented products and services, including data platforms.
- Support high data sharing between multiple entities across public clouds.
- Minimize the cost of data production.
- Support the curation and preservation of valuable datasets.
- Enable the creation of data pipelines to ensure data quality and format consistency.
- Facilitate the integration of data and analytical models and services into the existing IT landscape.
- Allow developers to focus on developing value-added analytic services rather than spending time on creating data-related infrastructure.
1) Data Flow from producers to consumers is safe
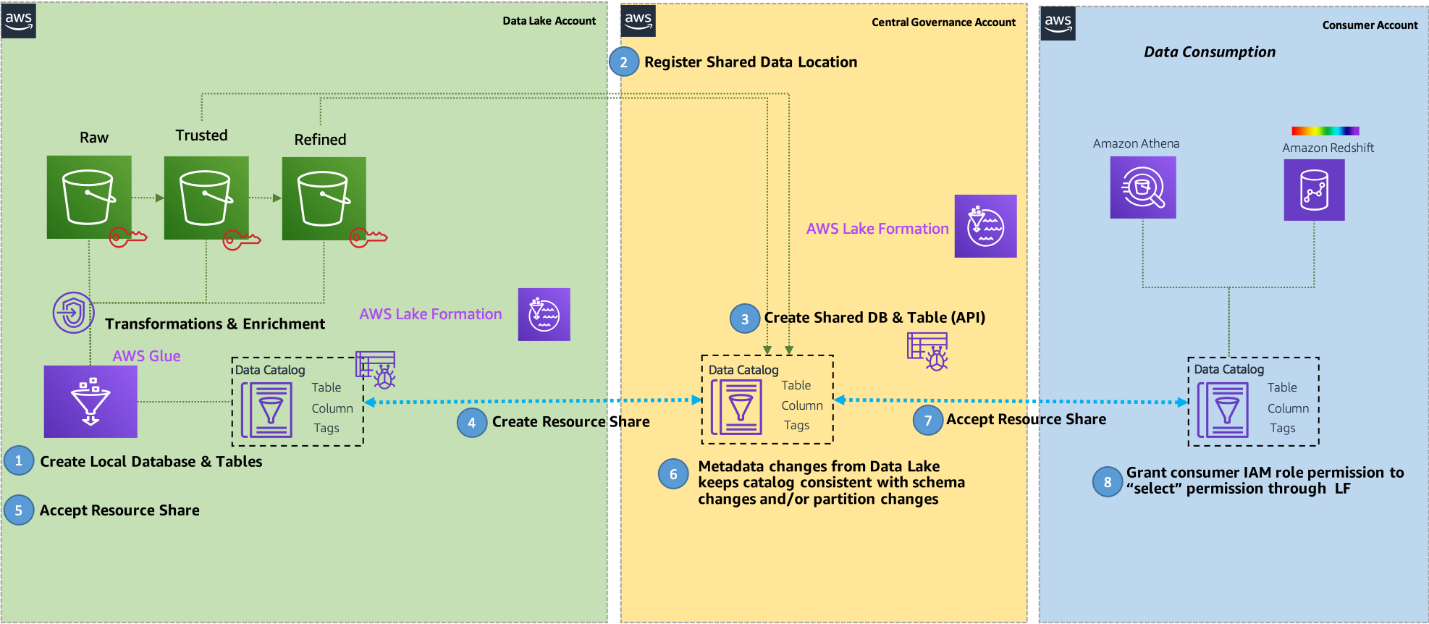
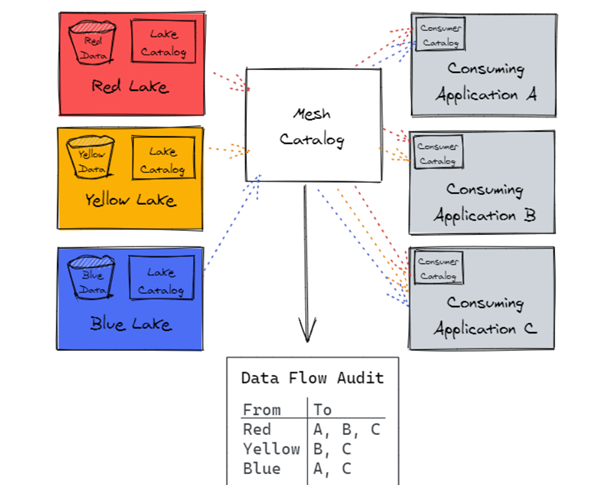
If you’re wondering how you could define a producer domain, it is right there in an AWS account and uses Amazon Simple Storage Service (Amazon S3) buckets to store raw and transformed data. Its ETL stack uses AWS Glue to process and prepare the data before being cataloged into a Lake Formation Data Catalog in its account. It also has a toolset to help perform analytics and machine learning on the data. Similarly, a consumer domain would include tools to analyze and perform machine learning on the data. A central data governance account is used to share datasets securely between the producers and consumers. But it doesn’t involve copying the data; it only shares data through the metadata. This ensures that ownership and control stay with the producer.
2) Data Mesh and Data-Driven Organizations
Data-driven organizations use data to make better decisions and deliver better outcomes. They apply data for business decisions, improve their processes and products, manage operations more effectively, and drive organizational change and continuous improvement. Data-driven organizations leverage big data analytics, advanced technology, automation, mobile devices, cloud computing, and social media to transform organizations into more nimble entities that can quickly adapt to changing market conditions.
The approach to designing a data mesh builds on the same architecture, principles, and practices that underlie Amazon EC2, Amazon S3, AWS CloudFront, and other components of the EC2 service.
Firstly you have to create a foundation for building data platforms. Data platforms enable producers and consumers to share data on an open and reliable network easily. The purpose of this is to help people to get the data that they need to improve their lives. Once you have the data, you can use that data to learn about your customers, employees, suppliers, competitors, and more. The data that you need to build a data platform can be anything. You can use it to learn more about your customers or your employees. You can even use it to learn more about your suppliers, competitors, or yourself.
The commonality of the approach allows data producers to embed data or metadata at the source, which enables data consumers to understand it and use it to meet their requirements. This is made possible because the data producers provide the data in a structured way to be easily understood and processed. Metadata is essentially extra data that describes data. Metadata is different than data because it’s often attached to a piece of information. It’s added to ensure the information is understandable to the end user. Data producers can easily add this metadata to the information in a way that helps them understand the information and process it further. Business rules are embedded within the metadata, meaning the data consumer can apply them to transform the data as they wish. Rules can be defined based on regulatory definitions, industry standards, or personal preferences. For example, the business can add BCBS239 to the metadata to define the data’s regulatory requirements, which enables the data consumer to report the data accordingly. These rules can also be extended to add additional standards, such as SOX reporting requirements, for the data consumer to understand and transform the data. You can check here how a renowned company utilized the data mesh architecture to drive significant values to enhance their enterprise data platform.
3) Data Mesh in IT products
By leveraging the interoperability provided by AWS’s data mesh, customers can integrate new data products into their existing data pipelines and use the same set of tools and techniques to make the data transformation work across many data stores and analytical applications.
The AWS Data Pipeline Service creates the infrastructure and tools for developers to build and manage data integration projects. This service can transform data in one or more ways and apply analytics to the transformed data.
Data Pipeline can use S3 as the underlying storage mechanism, but it can also use other data stores, including Amazon Redshift, Amazon Kinesis, Amazon DynamoDB, Amazon Athena, and others.
You can also create your data stores and products with APIs backed by Amazon API Gateway and Amazon S3. API gateway makes it easy for customers to publish data products to the cloud and consume the data through a web browser.
When a data product is ready to be published as an API and consumed by an application, AWS Data Pipeline creates an instance of the data product and runs the required code.
4) Data Mesh in AI and Machine Learning
The data mesh architecture lets you curate a set of curated data products from across different accounts in an environment where you can perform the actions needed to make them applicable to your data science applications. You can make data sets available to end users with the Lake Formation tool. The SageMaker platform makes it easy to create a data mesh architecture. It lets you create and deploy your multi-account data science environment.
SageMaker provides an ML platform with key capabilities around data management, data science experimentation, model training, model hosting, workflow automation, and CI/CD pipelines for production.
5) Enabling Financial Regulatory Data Collection
Many financial institutions around the world create regulatory reporting data products. They use the AWS Data Exchange API to publish those reports to the public. However, regulatory reporting data changes, and the API is not always aware of the revision. In such cases, the regulator (the data consumer) can pull a report modification into their system when they want to analyze the data. A normalization procedure makes the data consistent so that it can be searched, analyzed, and visualized with standard software. The API allows each producer of reporting data to describe its format in simple machine-readable documents, making it easy for a regulator to create a single view of the reporting data.
6) Data Mesh in reducing cost and risk for the companies
To this day, banking customers still don’t fully appreciate how much cloud-based technologies have changed the role that financial transaction services (FTS) professionals can play in their organizations. Using data-rich information about transactions and accounts to help make more informed decisions and reduce cost, capital, liquidity, and funding usage is an example of what FTS professionals can now do. Data mesh solutions can help FTS professionals use advanced analytics to learn more about their processes and activities. This, in turn, helps to become more effective and efficient, even when there is a limited amount of resources to devote to these roles.

The architectural design of Data Mesh on AWS with Lake formation and other services
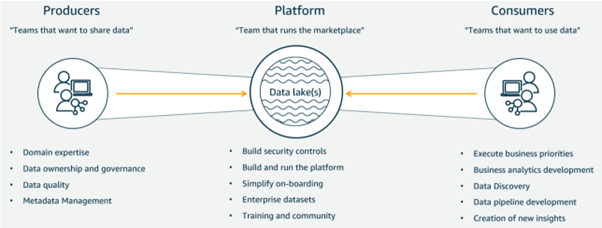
Data platforms consist of three parts:
- The data providers
- The platform provider
- The consumers of the data.
Some companies are collecting lots of information from their customers, and they want to share that information with trusted partners in a secure manner. This is done through a data lake that stores the data. Managing all this information has become a challenge. Companies are struggling with how to manage permissions on data lakes. To control the permissions, AWS provides the IAM roles and authentication facilities to ensure whether or not the data is maintained and excessed by the concerning authorities. Here need to set up some rules and guidelines specific to those permissions. They can control the access to the data that they have collected. If they want to control the access to the data, they will set up permission policies on the data lake.
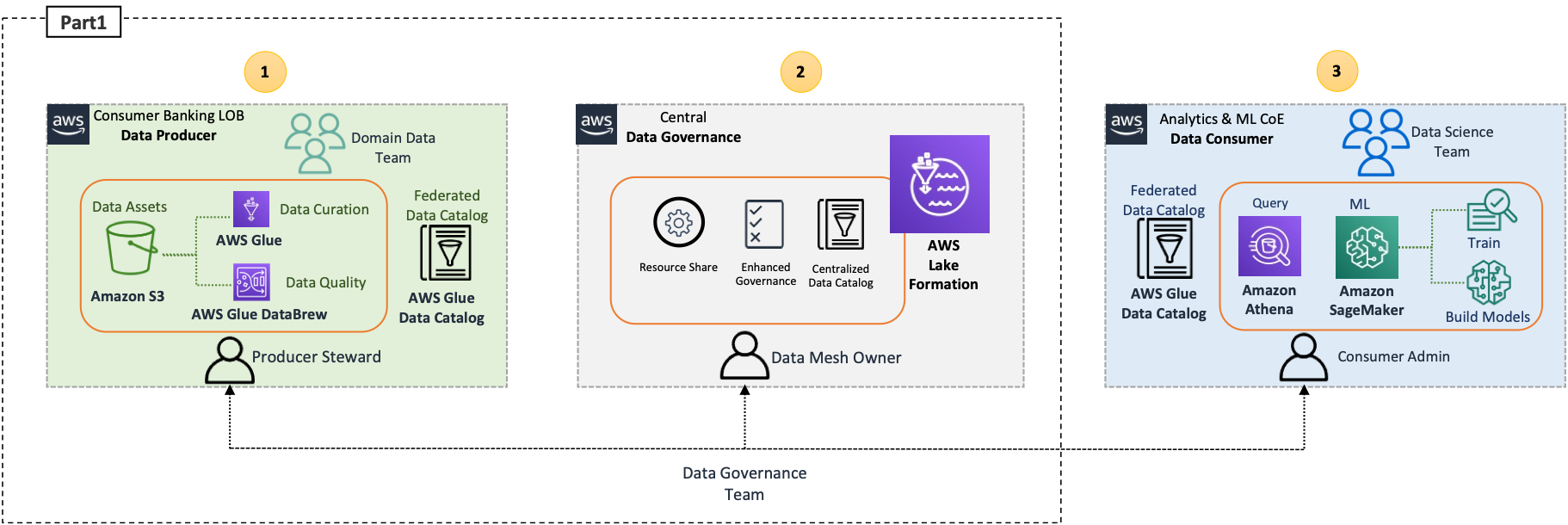
Each data domain – producer, consumer, and governance — is responsible for building its technology stack. But, with AWS native services, Lake House Architecture offers a repeatable blueprint that organizations can use to scale their data mesh design. A consistent technical foundation helps ensure that your organization can integrate AWS native analytics services with the Lake House architecture. The technology is consistent across all services, so features are supported, scale and performance are baked in, and costs remain low. In Data Mesh architecture AWS enforces control decisions through in-place consumption and also provides cross-enterprise visibility of data consumption
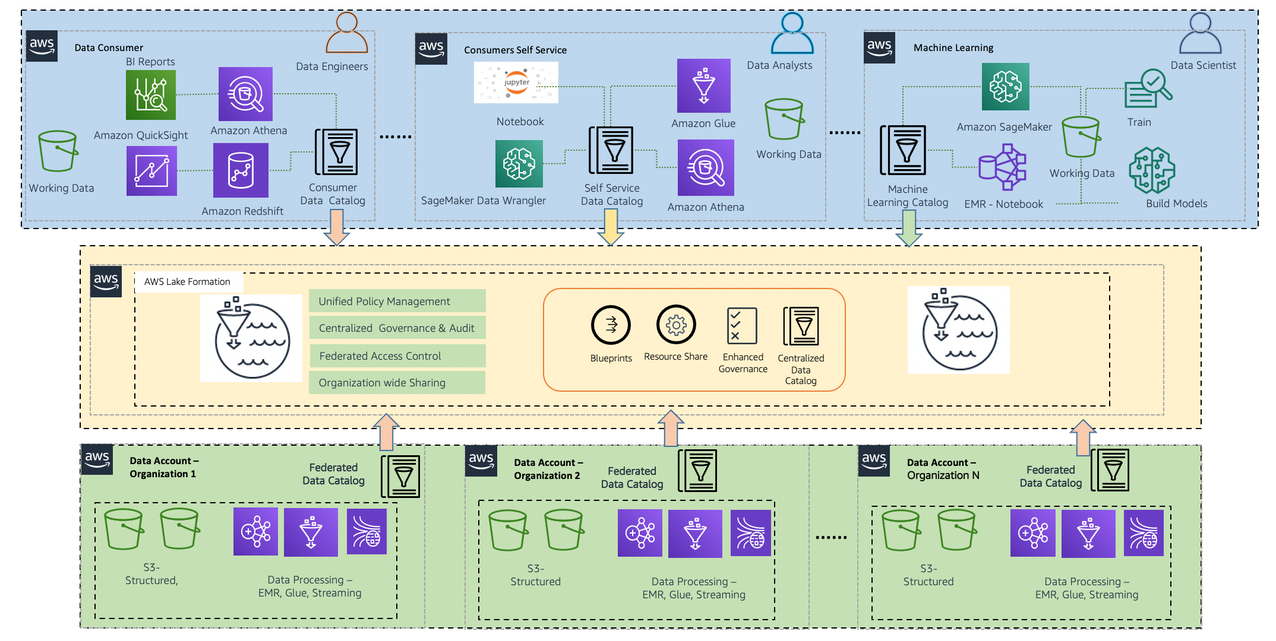
The central data governance account doesn’t store any data in itself; it only provides features allowing producers to register and create catalog entries with AWS Glue from all their S3 buckets. The data that is stored in it consists of logs only. The account is centrally defined, ensuring data governance policies are enforced across all data analytics applications. Users are only authorized to access the data using a role, with governance and auditing provided in a single place. Lake Formation centrally manages all data access across resources and enables enterprise-wide data sharing through resource shares.
Conclusion
Cloud computing can be daunting, especially when implementing a data mesh. That’s why it helps to use managed and serverless services. You can do that by leveraging AWS Glue, Lake Formation, Athena, and Redshift Spectrum, to name a few. These services offer a well-understood, performant, scalable, and cost-effective solution to ingest, prepare, and serve data.
It doesn’t matter if you’re an analyst, developer, business user, or data scientist. If you can access data, you can leverage a data mesh.
And lastly, when using AWS as the underlying infrastructure to host a data mesh platform, you can manage your infrastructure, including security.