
Introduction
Hyperparameter tuning is a machine learning concept which is the problem of selecting a set of most optimal Hyperparameters in order to learn an algorithm. It basically performs the role of a control variable which is responsible for controlling the learning process. As far as Hyperparameter optimization is concerned, it is considered to be a crucial step in the development of a machine learning model.
Amazon SageMaker jumps into the picture to create ease for the users by allowing them to tune more than one algorithm concurrently. You will find information regarding the following topics in this guide.
- How to set up a Hyperparameter tuning job
- How to cover tuning job settings
- How to train job definitions
- How to tune job configuration
There are two approaches which can be followed for managing Hyperparameter tuning jobs; console-based and API. We will further dive into the details in the later section of this guide.
Components of a Tuning Job
It is important to know that in Amazon SageMaker, a Hyperparameter tuning job consists of three important components:
- Tuning Job Settings
- Training Job Definitions
- Tuning Job Configuration
The setting of the setup depends on the number of algorithms you are trying to tune. Whenever you select a particular tuning job setting then it will be applied to all the algorithms present in the job. Some of the tuning job settings are warm start, tuning strategy and early stopping. Warm start and early stop have their own advantages like when you decide to use warm start then you will get an upper hand of leveraging results from the previous tuning jobs. In case of early stopping, the compute time will be reduced significantly. Warm start and early stopping are meant to be used for single-algorithm tuning jobs only.
Now comes the tuning strategy options which are random, Bayesian and Hyperband. When we discuss training job definitions then there are three things associated with it which the user has to provide as well; name, source of the algorithm and the ranges of Hyperparameter for every algorithm.
Getting Started
As told before, there are two options for the user to initiate a Hyperparameter tuning job. Both approaches have their own pros. Like if you decide to opt for the console-based option then you will have a user-friendly interface using which you can clone, create or even tag the jobs. In the case of API, you will have to go through in-depth details and instructions.
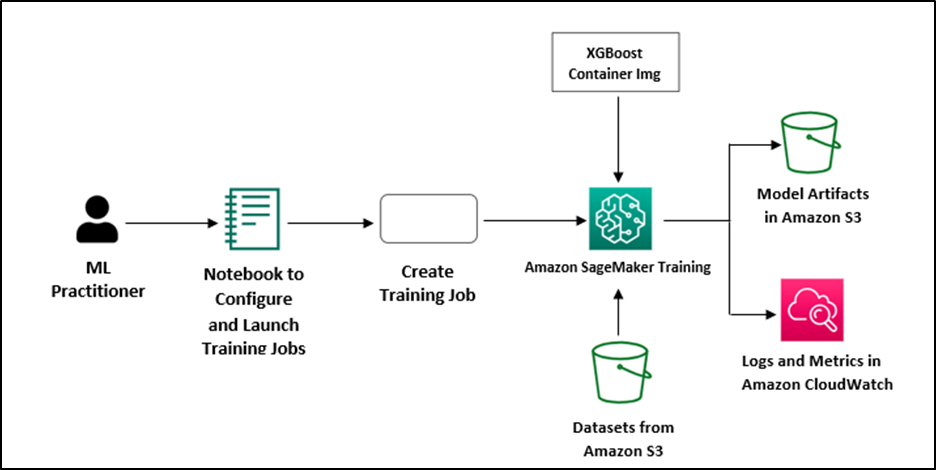
Creating Training Job Definitions
Before jumping on to the configuration part, it is essential to start by defining training job definitions for every algorithm to be tuned. For this you need to initialize estimators for every algorithm, specify input data locations and set Hyperparameters.
Let’s take an example where we want to initialize the estimators for XGBoost along with Linear Learner. For this, we need to set the static Hyperparameters and also define input data locations in Amazon S3. All these training job definitions are critical because they serve as the base for the succeeding Hyperparameter tuning.
Define Resources and Settings for Your Tuning Job
Once you are done with the first step, the next one involves the following:
- Initializing a tuner
- Specifying Hyperparameter Ranges
- Setting Up Objective Metric
In this section, you will get to know about the code examples related to the tuning process of a single algorithm as well as multiple algorithms. There is an ease for the users to customize the tuning strategy such as using the Bayesian optimization and setting the resource constraints like the max number of regular as well as parallel jobs. Metric definitions are used for accurate tracking.
Running Your HPO Tuning Job
In order to run the Hyperparameter tuning job you will be needing an initialized tuner and a set of defined training inputs. The code examples will give you an overall view regarding the execution of tuning jobs. They will emphasize on utilizing the flexibility of SageMaker’s HyperparameterTuner class. The process for both the situations, either running the job with one algorithm or with multiple algorithms, remain streamlined. This way the users will have an upper hand in fine-tuning and optimizing the machine learning models effectively.
Managing Hyperparameter Tuning and Training Jobs
As the number of training jobs within a tuning job starts increasing their management becomes difficult too. By using Amazon SageMaker you can use a console which will help you to access and monitor the Hyperparameter tuning jobs. Users will have the authority to get insights regarding the training jobs, training jobs definitions and identifying which model is the best performing one. For the sake of time convenience, you can use the cloning feature which will allow you to replicate the job settings.
Prerequisites
You must have the following prerequisites installed before diving into the implementation part.
- A working AWS account
- Access of an Administrator User
- An up and running SageMaker notebook instance
Creating a Notebook Instance
- Go to the website https://console.aws.amazon.com/sagemaker/
- Open the SageMaker console
- From the running notebook instances, open a single instance by clicking on “Open” option
- In order to create a new notebook, go to Files option, select New and then choose conda_python3
Get the Amazon SageMaker Boto3 Client
Open Jupyter notebook and import the necessary libraries. Along with this, create a Boto3 client for the SageMaker.
import sagemaker
import boto3
import numpy as np
import pandas as pd
from time import gmtime, strftime
import os
region = boto3.Session().region_name
smclient = boto3.Session().client('sagemaker')Get the SageMaker Execution Role
The ARN (Amazon Resource Name) of the IAM execution role will be attached to the notebook instance, retrieve it
from sagemaker import get_execution_role
role = get_execution_role()
print(role)Use an Amazon S3 Bucket for Input and Output
In order to upload your training datasets and save the output data, you will need to set an S3 bucket. There are two types of buckets available; default and custom. You can use either one of these.
sess = sagemaker.Session()
bucket = sess.default_bucket() # Use default S3 bucket
prefix = 'DEMO-automatic-model-tuning-xgboost-dm'Download, Prepare, and Upload Training Data
Now it’s time to download and prepare the training dataset. In this particular example, we have used a dataset of bank customer information for the purpose of predicting term deposit enrollment.
!wget -N https://archive.ics.uci.edu/ml/machine-learning-databases/00222/bank-additional.zip
!unzip -o bank-additional.zip
data = pd.read_csv('./bank-additional/bank-additional-full.csv', sep=';')
# Perform data preparation steps
# ...
# Upload data to S3 bucket
boto3.Session().resource('s3').Bucket(bucket).Object(os.path.join(prefix, 'train/train.csv')).upload_file('train.csv')Configure and Launch a Hyperparameter Tuning Job
We will now begin configuring the Hyperparameter tuning job with the help of low-level SDK for Python. Define the related components of a Hyperparameter tuning job configuration such as parameter ranges, resource limits and last but not the least objective metric.
tuning_job_config = {
"ParameterRanges": {
"CategoricalParameterRanges": [],
"ContinuousParameterRanges": [
{"MaxValue": "1", "MinValue": "0", "Name": "eta"},
{"MaxValue": "2", "MinValue": "0", "Name": "alpha"},
{"MaxValue": "10", "MinValue": "1", "Name": "min_child_weight"}
],
"IntegerParameterRanges": [
{"MaxValue": "10", "MinValue": "1", "Name": "max_depth"}
]
},
"ResourceLimits": {
"MaxNumberOfTrainingJobs": 20,
"MaxParallelTrainingJobs": 3
},
"Strategy": "Bayesian",
"HyperParameterTuningJobObjective": {
"MetricName": "validation:auc",
"Type": "Maximize"
},
"RandomSeed": 123
}Now it is time to define the training job specifications such as algorithm, output data, input data, resource configuration, role ARN, and stopping conditions:
# Define training job specifications
training_image = sagemaker.amazon.amazon_estimator.get_image_uri(region, 'xgboost', repo_version='1.0-1')
s3_input_train = 's3://{}/{}/train'.format(bucket, prefix)
s3_input_validation = 's3://{}/{}/validation/'.format(bucket, prefix)
training_job_definition = {
"AlgorithmSpecification": {
"TrainingImage": training_image,
"TrainingInputMode": "File"
},
"InputDataConfig": [
{"ChannelName": "train", "CompressionType": "None", "ContentType": "csv", "DataSource": {...}},
{"ChannelName": "validation", "CompressionType": "None", "ContentType": "csv", "DataSource": {...}}
],
"OutputDataConfig": {"S3OutputPath": "s3://{}/{}/output".format(bucket, prefix)},
"ResourceConfig": {"InstanceCount": 2, "InstanceType": "ml.c4.2xlarge", "VolumeSizeInGB": 10},
"RoleArn": role,
"StaticHyperParameters": {...},
"StoppingCondition": {"MaxRuntimeInSeconds": 43200}
}
Save to grepper
Name and launch the hyperparameter tuning job:
python
Copy code
tuning_job_name = "MyTuningJob"
smclient.create_hyper_parameter_tuning_job(
HyperParameterTuningJobName=tuning_job_name,
HyperParameterTuningJobConfig=tuning_job_config,
TrainingJobDefinition=training_job_definition
)Monitoring the Progress of a Hyperparameter Tuning Job
You can easily track the training jobs status in the SageMaker console which is launched by the Hyperparameter tuning job.
View the Best Training Job
As soon as the Hyperparameter tuning job part is done, it is time to identify the best training job among the others on the basis of objective metric. The best model should be deployed as a SageMaker endpoint for inference.
Clean Up
All the resources which were created for the demonstration of this example should be deleted immediately to avoid unnecessary charges. For this purpose, use the AWS Management Console and delete the resources including S3 bucket, notebook instance and IAM role.
For detailed roadmap you can also watch this video tutorial to make stuff easier:
Conclusion
To become an expert in Hyperparameter optimization using Amazon SageMaker, you need to have comprehensive details regarding tuning job settings, training job definitions, job configuration etc. The sample example shown above consisted of every step from the creation of resources to deleting them. For your better understanding, you can experiment with other algorithms as well by using SageMaker’s powerful capabilities.
A Software Engineer by profession and a Writer by passion