
Amazon Rekognition is a powerful service that enables developers to integrate image and video analysis capabilities into their applications. It allows you to analyze images for objects, faces, text, and more, opening doors for numerous use cases like facial recognition, content moderation, and object detection.
In this blog post, I will guide you through the process of using Amazon Rekognition to build a face detection application. We’ll create a straightforward Python application with Streamlit, an open-source library designed to simplify the development of interactive web applications. Streamlit allows developers to quickly build and share custom apps by writing Python scripts, offering features like real-time updates, user interface components (such as sliders and file uploaders etc), and seamless integration with popular data libraries.
Prerequisites
Before you begin you need:
- An aws account with a full administrative privileges
- Python runtime environment
- AWS Command Line Interface (CLI)
Step 1: Create an IAM User
The face detection application will programmatically access AWS Rekognition to analyze images and detect faces. To enable this, you need to create an IAM user with the appropriate permissions to use Amazon Rekognition. This ensures secure and authorized access to the service.
Here’s how to create and configure IAM user:
- Navigate to the Identity Access Management (IAM) Console.
- Go to the Users link in the left side navigation panel
- Click Create User, and proceed with the outlined steps.
Step 2: Authorize the user to access Amazon Rekognition
After creating the user, it is necessary to grant them access to Amazon Rekognition. To do this we can create a user group with the appropriate policy and add the user to the user group.
- In the navigation menu, click User Groups, then choose Create Group.
- Create the user group by providing a group name and attaching “AmazonRekognitionReadOnlyAccess” policy to it.
- Open the newly created user group and click on Add Users button.
- From the list of users choose the user you want to assign to access Amazon Rekognition service.
Step 3: Generate Access Key
To generate an Access Key for the user
- Go to the security credentials tab, scroll down to the “Access keys” section.
- In the Access keys section, choose Create access key.
- On the Access key best practices & alternatives page, choose “Command Line Interface (CLI)” tick the “I understand the above recommendation and want to proceed to create an access key.” check box and then click Next.
- On the Retrieve access keys page, choose either Show to reveal the value of your user’s secret access key, or Download .csv file. This is your only opportunity to save your secret access key. After you’ve saved your secret access key in a secure location, choose Done.
Step 4: Initialize Python Application and Install the necessary packages
Now that we have all aws config setups completed we can now create our Python app. This step assumes you have Python installed and running.
- Open Windows Command Prompt
- CD into your chosen project directory
- Install the boto3 package, the AWS SDK for Python
- Install Streamlit library
- Install Pillow, a powerful Python library for image-processing tasks
pip install boto3 Streamlit pillow (installs all three packages in one go)
Note: The boto3 package is a Python library provided by Amazon Web Services (AWS) to interact with various AWS services programmatically.
Pillow, often referred to as the Python Imaging Library (PIL), enables applications to open, manipulate, and save images in a variety of formats.
Step 5: Set up authentication details
At this point, we are setting up our application to interact with AWS services. To achieve this, we’ll be configuring our AWS Command Line Interface (CLI) with the credentials of the user we’ve already created. Assuming you have the AWS CLI installed, we prefer configuring the user credentials through the CLI rather than hard-coding them into our code. This approach enhances security, as storing sensitive credentials directly in the code is not recommended. Following the AWS credentials provider chain, the AWS SDK will automatically search and use the credential within the AWS CLI, ensuring that our application can securely access AWS bedrock.
- Open the command prompt and initiate the user configuration by entering the command “aws configure.”
- Enter the Access Key ID.
- Provide the Secret Access Key.
- Specify the Region.
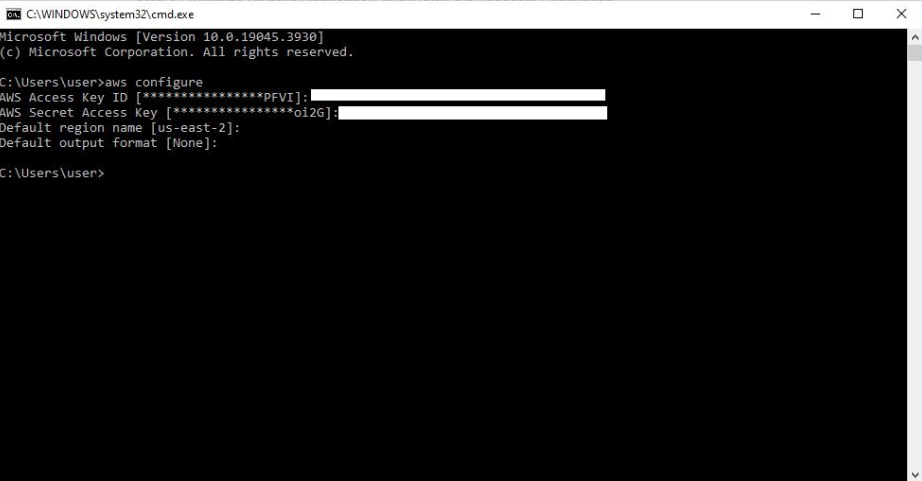
Screenshot of Windows command prompt window showing the process of aws user configuration
Step 6: Application Implementation and Integration with Amazon Rekognition
Let’s dive into the steps involved in building and integrating a face detection application with Amazon Rekognition.
Application Workflow
Here’s the step-by-step flow of the application:
- Image Upload and Display: The application provides a user interface for uploading an image, displays the uploaded image to the user.
- Convert the uploaded image into a byte stream for processing
- Send Image to Amazon Rekognition: The byte stream is sent to Amazon Rekognition for analysis.
- Amazon Rekognition processes the image and returns a list of detected face details.
- Draw Bounding Boxes: Using the face details, bounding boxes are drawn around detected faces, and the output image is displayed to the user along with confidence scores.
import streamlit as st
import boto3
from PIL import Image, ImageDraw
rekognition_client = boto3.client('rekognition')
def detect_faces(image_bytes):
response = rekognition_client.detect_faces(
Image={'Bytes': image_bytes},
Attributes=['ALL']
)
return response['FaceDetails']
def draw_boxes(image, face_details):
draw = ImageDraw.Draw(image)
for face in face_details:
box = face['BoundingBox']
width, height = image.size
left = box['Left'] * width
top = box['Top'] * height
right = left + (box['Width'] * width)
bottom = top + (box['Height'] * height)
draw.rectangle([left, top, right, bottom], outline="red", width=3)
return image
st.title("Amazon Rekognition: Face Detection")
st.write("Upload an image to detect faces using Amazon Rekognition.")
uploaded_file = st.file_uploader("Choose an image", type=["jpg", "jpeg", "png"])
if uploaded_file:
try:
image = Image.open(uploaded_file)
st.image(image, caption="Uploaded Image", use_column_width=True)
uploaded_file.seek(0)
image_bytes = uploaded_file.read()
if len(image_bytes) == 0:
st.error("Failed to read the image. Please upload a valid image.")
else:
with st.spinner("Analyzing..."):
face_details = detect_faces(image_bytes)
if face_details:
st.success(f"Detected {len(face_details)} face(s).")
boxed_image = draw_boxes(image, face_details)
st.image(boxed_image, caption="Image with Detected Faces", use_column_width=True)
st.write("Face Details:")
for i, face in enumerate(face_details):
st.write(f"Face {i + 1}:")
st.write(f" - Confidence: {face['Confidence']:.2f}%")
else:
st.warning("No faces detected.")
except Exception as e:
st.error(f"Error processing the image: {e}")
Face detection application using Amazon Rekognition python implementation
Let’s break down the code statement by statement:
Imports:
import streamlit as st
import boto3
from PIL import Image, ImageDrawThe code begins by importing the Streamlit library as st, which is used to build the user interface for the application. It also imports the boto3 library to interact with AWS services. Lastly, it imports the Image and ImageDraw modules from the PIL package. The Image module provides core functionality for opening, creating, and manipulating images, while the ImageDraw module offers methods to draw shapes such as rectangles, circles, lines, and polygons on an image.
Setting Up the Rekognition Client:
rekognition_client = boto3.client('rekognition')Here, we initialize the Rekognition client. Since AWS CLI credentials are preconfigured, the boto3 client automatically uses those credentials to authenticate.
Detecting Faces Using Rekognition:
def detect_faces(image_bytes):
response = rekognition_client.detect_faces(
Image={'Bytes': image_bytes},
Attributes=['ALL']
)
return response['FaceDetails']This code block defines a function named detect_faces which takes a parameter image_bytes(The uploaded image, read as a byte stream) and is responsible for sending the image data to Amazon Rekognition’s service for face detection.
The line “response = rekognition_client.detect_faces()” calls the “detect_faces” method from the rekognition_client.
In the “detect_faces” function, the “image_bytes” input represents the uploaded image, which is passed as a byte stream to the Rekognition service. By setting the “Attributes = [‘ALL’]” parameter, the function ensures that the response will include all available face details, such as the age range, emotions, and facial landmarks.
Once the API processes the image, it returns a response that contains a list of face details, including key information like bounding box coordinates, confidence scores, and emotions for each detected face. This response is then returned by the “detect_faces” function.
Drawing Bounding Boxes on Detected Faces:
def draw_boxes(image, face_details):
draw = ImageDraw.Draw(image)
for face in face_details:
box = face['BoundingBox']
width, height = image.size
left = box['Left'] * width
top = box['Top'] * height
right = left + (box['Width'] * width)
bottom = top + (box['Height'] * height)
draw.rectangle([left, top, right, bottom], outline="red", width=3)
return imageThe draw_boxes function is responsible for drawing bounding boxes around the faces detected in the image. It begins by creating a drawing context for the image using “ImageDraw” from PIL library using “Draw()” method. Then, for each face in the “face_details” list, it retrieves the bounding box coordinates (which are provided as ratios of the image’s width and height by Amazon Rekognition) and scales them to the actual dimensions of the image. Using these scaled coordinates, the function draws a red rectangle around each detected face with “draw.rectangle()” method. The result is an image with red rectangles outlining the faces, making them visually identifiable. The function returns the modified image with these drawn boxes.
Streamlit User Interface Display
st.title("Amazon Rekognition: Face Detection")
st.write("Upload an image to detect faces using Amazon Rekognition.")Handling File Uploads in Streamlit:
uploaded_file = st.file_uploader("Choose an image", type=["jpg", "jpeg", "png"])Here Streamlit’s “file_uploader” widget allows users to upload image files. The supported file types are restricted to .jpg, .jpeg, and .png
Reading and Displaying Uploaded Images:
if uploaded_file:
try:
image = Image.open(uploaded_file)
st.image(image, caption="Uploaded Image", use_column_width=True)
uploaded_file.seek(0)
image_bytes = uploaded_file.read()
if len(image_bytes) == 0:
st.error("Failed. Please upload a valid image.")
else:
with st.spinner("Analyzing..."):
face_details = detect_faces(image_bytes)
if face_details:
st.success(f"Detected {len(face_details)} face(s).")
boxed_image = draw_boxes(image, face_details)
st.image(boxed_image, caption="Image with Detected Faces",
use_column_width=True)
st.write("Face Details:")
for i, face in enumerate(face_details):
st.write(f"Face {i + 1}:")
st.write(f" - Confidence: {face['Confidence']:.2f}%")
else:
st.warning("No faces detected.")
except Exception as e:
st.error(f"Error processing the image: {e}")
This code snippet is the core logic for processing and analyzing uploaded images. It handles file uploads, performs facial detection, and displays results interactively. Here’s a breakdown of the key components:
File Upload and Image Display:
- The ‘if uploaded_file:’ block checks if a file has been uploaded.
- The uploaded file is opened as an image using ‘Image.open(uploaded_file)’ from the Pillow library.
- The image is displayed in the app using ‘st.image’ with the caption “Uploaded Image” and scaled to fit the column width.
File Reset and Byte Stream Preparation:
- ‘uploaded_file.seek(0)’ resets the file pointer to the start to ensure the file is read correctly.
- ‘uploaded_file.read()’ reads the image file into a byte stream, ‘image_bytes’, which is necessary for further processing (e.g., sending to an API).
Validation and Error Handling:
- The ‘if len(image_bytes) == 0:’ block checks if the file has been read successfully.
- If the byte stream is empty, an error message is shown using ‘st.error’, asking the user to upload a valid image.
- A ‘try-except’ block ensures robust error handling:
- If any exceptions occur during image processing, a friendly error message is displayed with the specific issue.
Face Detection:
- If the file is valid, a loading spinner (st.spinner) indicates that the app is analyzing the image.
- The ‘detect_faces(image_bytes)’ function (assumed to call AWS Rekognition or similar) processes the image to detect faces.
Displaying Results:
- If faces are detected:
- A success message (st.success) displays the number of faces found.
- Detected faces are highlighted with bounding boxes using ‘draw_boxes(image, face_details)’
- The modified image with the bounding boxes is displayed using ‘st.image’.
- For each detected face:
- The app lists detailed information, including the confidence level of the detection, using ‘st.write’.
Handling No Faces Detected:
- If no faces are detected:
- A warning message (st.warning) informs the user.
Output

Snapshot of the Final Application UI

Screenshot of the image I uploaded to the face detection application
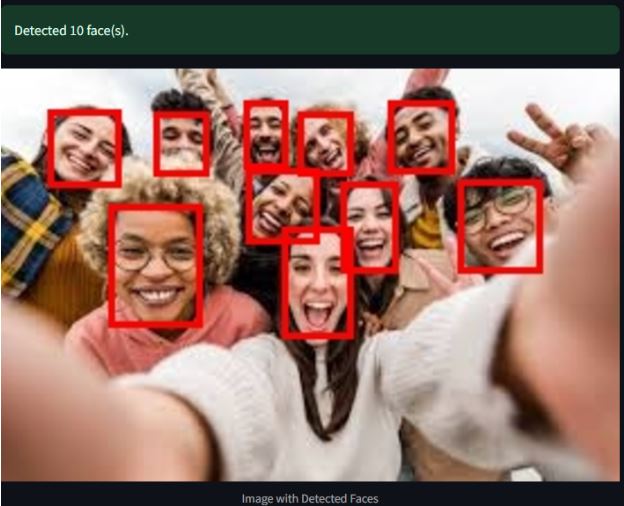
Screenshot of the response or output of Amazon Recognition

Screenshot of displayed information about faces detected
Conclusion
In this blog post, I’ve tried to demonstrate how quickly you can build and integrate a face detection application using Amazon Rekognition. This powerful service simplifies image analysis, allowing developers to focus on building user-centric applications without worrying about complex machine learning pipelines.
Feel free to explore further features of Amazon Rekognition, such as object detection or facial comparison, to unlock more potential in your applications!