
What is Data Analytics
Data analytics is the function of analyzing huge amounts of data to find patterns, trends, correlations, and insights that may be utilized to make better business choices. It includes collecting, organizing, converting, and analyzing data in order to extract useful data and support decision-making processes.
Data analytics interprets data and generates actionable insights using a variety of techniques and technologies such as statistical analysis, machine learning, data mining, and visualization. Organizations utilize data analytics to optimize operations, increase performance, comprehend consumer behavior, detect market trends, manage risks, and achieve a competitive advantage in their respective sectors.
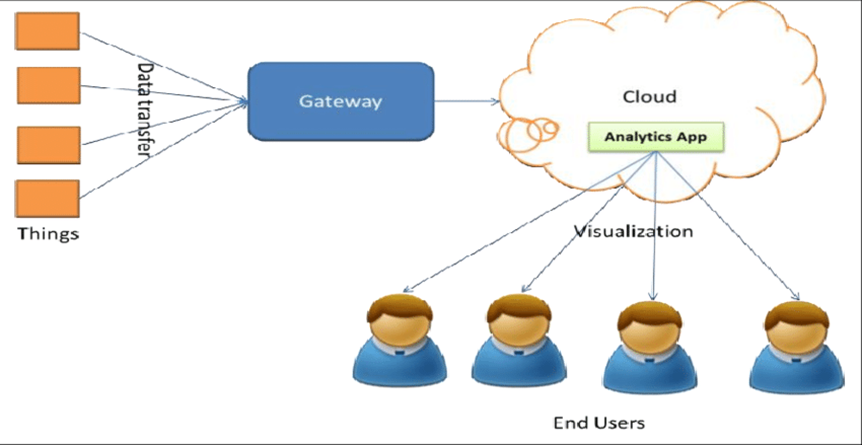
What is AWS Data Analytics?
AWS Data Analytics refers to a set of services offered by AWS that allow enterprises to efficiently and effectively analyze large volumes of data in the cloud. This set of services includes:
- Amazon Redshift
- Amazon EMR
- Amazon Athena
- Amazon QuickSight
- AWS Glue
These services handle many components of the data analytics pipeline, such as data warehousing, big data processing, ad hoc querying, data visualization, and data integration. AWS Data Analytics services provide scalability, flexibility, and cost-effectiveness, enabling enterprises to handle and analyze data of any amount or kind from many sources in real-time or batch mode.
Businesses that use AWS Data Analytics can derive significant insights from their data, make decisions based on data, increase operational efficiency, improve customer experiences, and drive innovation inside their enterprises.
AWS Athena
Amazon Athena is a serverless interactive query service or interactive data analysis tool designed to perform complicated queries in less time. Because of its serverless nature, it requires no infrastructure to administer or set up. It can swiftly analyze data using Amazon S3 and ordinary SQL. It does not even need to import the data into Athena.
All we need to do is point to the data in Amazon S3, build the schema, and start querying using ordinary SQL. With the help of Amazon Athena, we can process any data, whether it is structured, semi-structured, or unstructured, i.e., it can handle the data in CSV, Avro, or columnar formats like parquet and orc.
Amazon Athena works directly with S3 data. It operate as a distributed SQL engine for query execution, and it also use Apache Hive to create and modify tables and partitions. Some of the main perspectives required for working with Athena include.
- You need to have an AWS account.
- You should allow your account to export cost and use data to an S3 bucket.
- You can configure buckets for Athena to connect.
- Every time AWS writes to a bucket, it produces manifest files using metadata. In fact, it creates a folder named Athena under the technology AWS billing data bucket that only includes data.
- The US-West-2 region can also be utilized to ease the setup process.
- The final step is to download the new user’s credentials, which aid with indirect mapping to the database credentials.
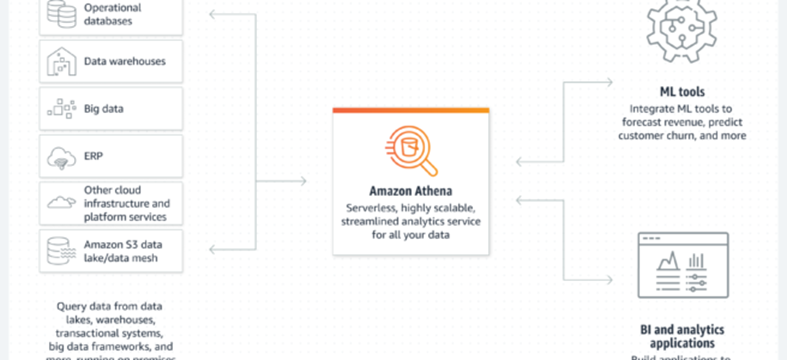
Query Amazon S3 Analytics data with Amazon Athena architecture:
There are three methods to use Athena.
- The AWS Management Console has a SQL editor, a wizard for building schemas and tables, and shows results inline. It’s an excellent way to get started.
- Athena supports ODBC and JDBC drivers, allowing you to connect to it using your preferred database application or library.
- The Athena SDK supports an asynchronous API. You perform a query, receive a unique ID, and then use that ID to track progress and obtain results.
Some important points of Athena.
- Athena supports a wide range of data types that may exist in your S3 buckets. These include CSV, JSON, ORC, Parquet, and Avro, which may be useful to remember.
- Athena does not care if your data in S3 is organized or semi-structured. It can interact with glue and the glue data catalog to arrange the data and make it queryable with a SQL statement.
- Athena also integrates with tools like as Jupiter, Zeppelin, and RStudio notebooks, allowing you to use it as a database.
- Athena may also use Amazon’s QuickSight visualization tool.
How much does Athena Cost
Athena price is based on only one variable: the amount of data required to conduct a query. Every time you make a query, Athena must scan all relevant data from S3, and Amazon costs $5 every terabyte scanned. The more you scan, the more you’ll pay. Aside from S3 storage, this scanning is the sole expense of utilizing Athena. This implies that if you don’t execute any queries, you won’t pay anything.
Amazon Redshift
Amazon Redshift enables you to conduct complicated analytical queries on massive datasets while providing quick query performance by dynamically spreading data and queries over numerous nodes. It enables you to effortlessly import and manipulate data from many sources, including Amazon DynamoDB, Amazon EMR, Amazon S3, and your transactional databases, into a single data warehouse for analytics.
Because of Amazon Redshift is a fully managed service with minimal administrative overhead, you can concentrate on your data analytics tasks rather than maintaining infrastructure. It handles all of the difficult duties associated with setting up and operating a data warehouse, such as providing capacity, monitoring and backing up your cluster, and applying patches and updates.
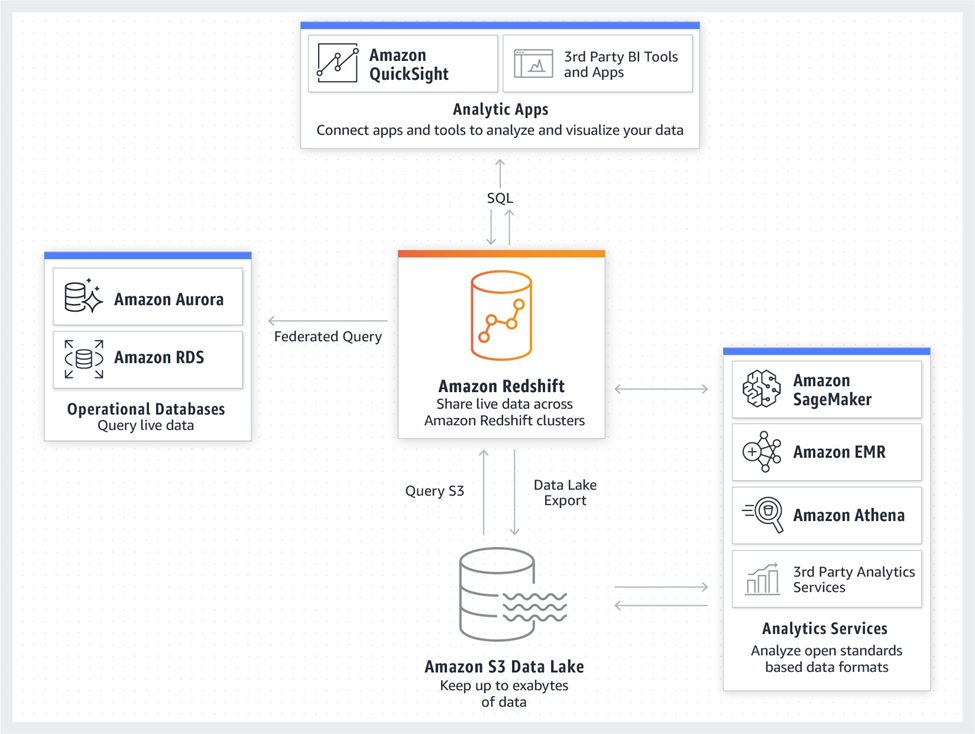
Simple overview architecture of AWS Redshift
AWS Redshift Deployment as Multi-AZ
Follow these steps to create an Amazon Redshift provisioned cluster in two Availability Zones.
- On the Amazon Redshift console, in the navigation pane, choose Clusters.
- Click on Create cluster.
- Choose one of the RA3 node types on the Node type drop-down menu. The Multi-AZ deployment option only becomes available when you choose an RA3 node type.
- For Multi-AZ deployment, select Multi-AZ option.
- For Number of nodes per AZ, enter the number of nodes that you need for your cluster.
Deployment by console

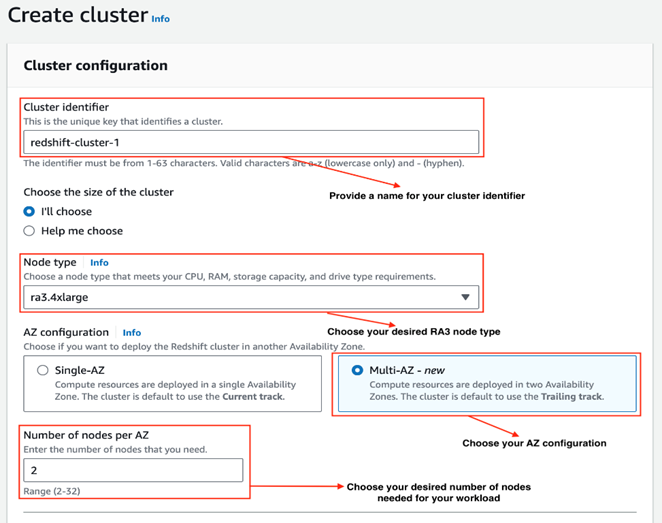
- Under the Database configurations, choose Admin user name and Admin user password.
- Turn Use defaults on next to Additional configurations to modify the default settings.
- Under Network and security, specify the following:
- For Virtual private cloud (VPC), choose the VPC you want to deploy the cluster in.
- For VPC security groups, either leave as default or add the security groups of your choice.
- For Cluster subnet group, either leave as default or add a cluster subnet group of your choice. For a Multi-AZ deployment, a cluster subnet group must include one subnet each from at least three or more different Availability Zones.
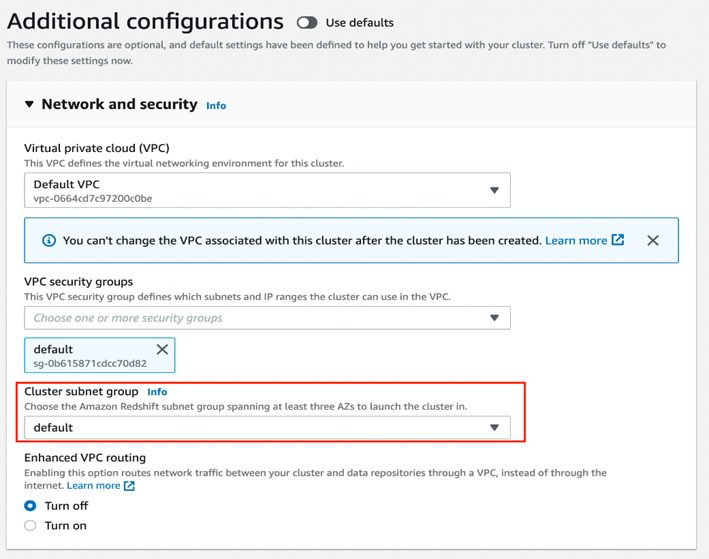
- Under Database configuration, for Database port, you either use the default value 5439 or choose a value from the range of 5431–5455 and 8191–8215.
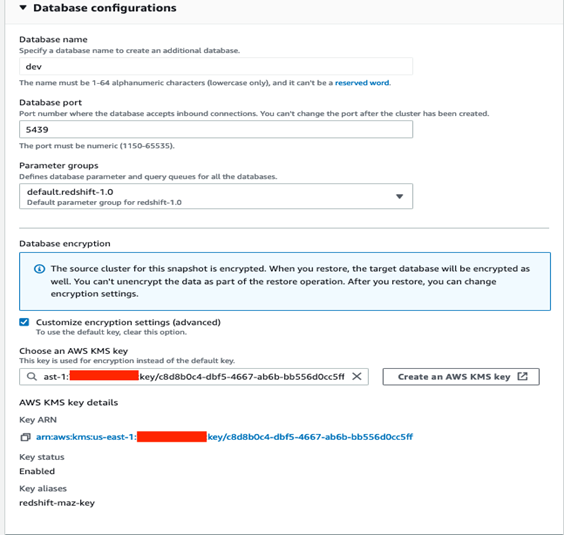
- Under Database configuration, in the Database encryption section, to use a custom AWS Key Management Service (AWS KMS) key other than the default KMS key, choose Customize encryption settings. This option is deselected by default.
- Under Choose an AWS KMS key, you can either choose an existing KMS key, or choose Create an AWS KMS key to create a new KMS key.
- Choose to Create cluster.
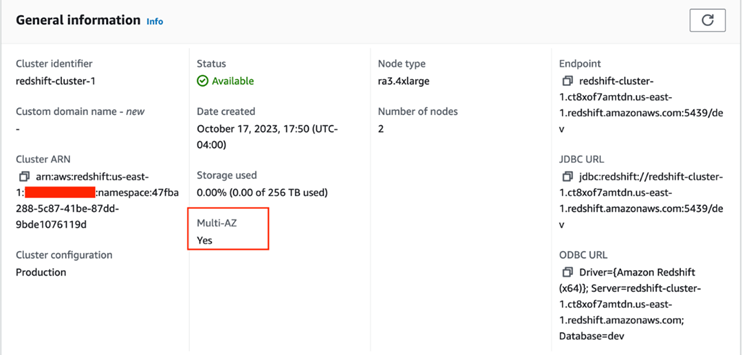
When the cluster creation succeeds, you can view the details on the cluster details page.
Under General information, you can see Multi-AZ as Yes.
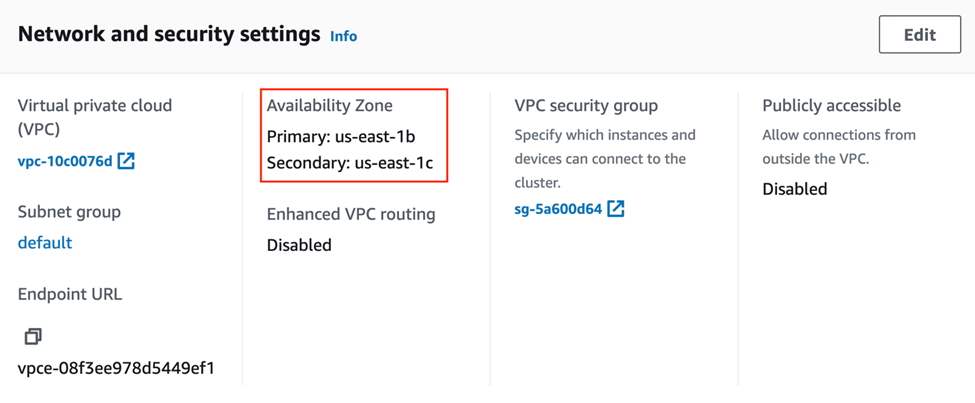
On the Properties tab, under Network and security settings, you can find the details on the primary and secondary Availability Zone.
Some Important points of AWS Redshift:
Performance optimized for analytics
Amazon Redshift is designed to handle high-performance analytics queries. It employs data optimization and distribution techniques to enable complicated searches in seconds, even on extremely large amounts of data.
Scale On Demand
Redshift supports on-demand scaling. You may quickly expand or reduce storage and compute capacity based on your business requirements, maintaining continuous performance.
Integration with BI Tools
It is compatible with a wide range of Business Intelligence (BI) tools, including Tableau, Power BI, and QuickSight, making it simple to generate useful visualizations and reports from Redshift data.
Security and Compliance
Amazon Redshift offers advanced security features, including data encryption at rest and in transit, two-factor authentication, and integration with AWS Identity and Access Management (IAM).
Backup and Fault Tolerance
Allows for automated backups as well as manual snapshot creation. Additionally, it automatically duplicates data to backup nodes, ensuring recovery in the event of failure.
What is the Amazon Redshift pricing model?
Amazon Redshift provides a flexible and cost-effective pricing strategy that is particularly adaptable to a variety of business requirements. Here is a detailed breakdown.
Cost Efficiency: One of Redshift’s key attractions is its affordable price. Amazon says that Redshift costs less than opponent data warehouses. Starting around $0.25 per hour (as of 2021), it can scale to handle petabytes of data and thousands of users.
Flexible pricing options.
Pay-as-you-go: This concept enables firms to pay only for the resources they utilize, resulting in efficient cost control.
On-demand Pricing: This strategy allows organizations to choose pricing that varies based on consumption, giving them flexibility without long-term obligations.
Additional models: Amazon Redshift provides additional price structures adapted to certain business requirements, allowing enterprises to select the best match for their needs.
Redshift vs Athena Basics.
| REDSHIFT | ATHENA | |
| Partitioning | Does not support direct partitioning by default Uses predefined distribution keys to optimize tables for parallel processing Poor manual partition key selection can dramatically impact query performance, so Redshift does it for you | Can partition by any key with up to 20,000 per table Supports several Serializer/Deserializer (SerDe) libraries for parsing data from different data formats: CSV, JSON, TSV, and Apache logs Does not support arrays or object identifier types |
| User Defined Functions | Supports UDFs with scalar and aggregate functions | Does not support UDFs |
| Data Formats and Types | Supports several Serializer/Deserializer (SerDe) libraries for parsing data from different data formats: CSV, JSON, TSV, and Apache logs Does not support arrays or object identifier types | Supports several Serializer/Deserializer (SerDe) libraries for parsing data from different data formats: CSV, JSON, TSV, Parquet, and ORC Beneficial due to Athena’s convenient data to query structure Supports complex data types like arrays, maps, and structs |
| Primary Key Constraint | Key not required Can duplicate data multiple times If needed, the key must be declared before data is loaded into the warehouse | Key not required Duplication exists only if already contained in S3 datasets |
Use Cases of Amazon Redshift and Amazon Athena
Both Amazon Redshift and Amazon Athena are versatile tools that can be used for a variety of data analytics use cases, including but not limited to:
- Business Intelligence and Reporting: Build interactive dashboards and reports to gain insights into your business operations, customer behavior, and market trends.
- Data Warehousing: Store and analyze large volumes of structured data from various sources, such as transactional databases, log files, and IoT sensors.
- Ad Hoc Analysis: Explore and analyze data on the fly without the need for pre-defined schemas or data models, allowing for agile decision-making and experimentation.
- Data Lake Analytics: Query and analyze data directly in your data lake on Amazon S3, leveraging the flexibility and scalability of serverless computing.
Conclusion:
In conclusion, Amazon Redshift and Amazon Athena are powerful data analytics tools on AWS, providing scalable, adaptable, and cost-effective solutions for processing and analyzing huge amounts of data. Whether you want a high-performance data warehouse for complicated analytics or a serverless query service for ad hoc analysis, these services provide you the tools you need to extract useful insights from your data. Businesses can leverage the benefits of Amazon Redshift and Amazon Athena to realize the full potential of their data, driving innovation and growth in today’s competitive market.
