
Introduction
In this article, we will delve deep into the world of Amazon FSx for Lustre and explore how it can transform your data processing capabilities. We will begin by understanding the concept of data bottlenecks in big data processing and their impact on organizations. Then, we will introduce Amazon FSx for Lustre as a powerful solution to overcome these bottlenecks and achieve lightning-fast insights. We will discuss the key features and benefits of FSx for Lustre, providing a comprehensive understanding of its capabilities.
Furthermore, we will explore real-world examples, best practices, and tips for leveraging FSx for Lustre effectively. Finally, we will conclude by summarizing the advantages of using FSx for Lustre and encouraging organizations to embrace this solution for their big data workloads.
In the era of big data organizations face the challenge of processing and analyzing vast amounts of data efficiently. However, the volume, variety, and velocity of data often lead to data bottlenecks which hinders the timely extraction of valuable insights. These bottlenecks can significantly impact an organization’s ability to make informed decisions, gain a competitive edge, and drive innovation.
Efficient data processing is crucial for organizations seeking to leverage their data effectively. The ability to quickly transform raw data into actionable insights can drive business growth, optimize operations, and enhance customer experiences. Therefore, finding a solution that overcomes data bottlenecks and enables lightning-fast data processing is of paramount importance.
This is where Amazon FSx for Lustre comes into the picture. As a high-performance file system offered by Amazon Web Services (AWS), FSx for Lustre is designed specifically to address data bottlenecks and revolutionize big data processing. By leveraging FSx for Lustre, organizations can unlock the full potential of their data, accelerate processing speeds, and gain real-time insights that drive their success.
Get ready to unlock the power of lightning-fast data processing with Amazon FSx for Lustre!
Lightning-Fast Data Processing with Amazon FSx for Lustre
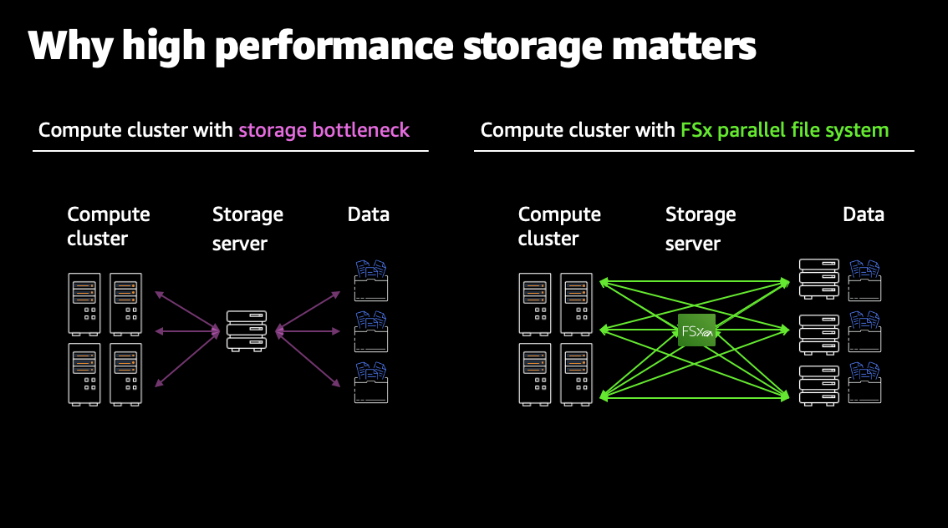
Amazon FSx for Lustre is built on a robust architecture that enables high-speed data processing, making it an ideal solution for compute-intensive workloads. FSx for Lustre employs a parallel file system design, which allows for concurrent read and write operations across multiple instances or compute nodes. This parallelism ensures that data processing tasks can be executed in parallel, significantly reducing processing time and accelerating insights generation.
The parallel file system capabilities of FSx for Lustre are crucial in achieving high-speed data processing. It enables organizations to distribute their data across multiple storage servers, allowing for simultaneous data access and processing from multiple compute instances. This parallel access to data ensures that workloads can scale horizontally, handling large volumes of data and compute-intensive tasks efficiently.
Organizations across various industries have experienced substantial performance gains with Amazon FSx for Lustre. For example, in the financial sector, hedge funds rely on FSx for Lustre to process large financial datasets and run complex algorithms for real-time trading analysis. By leveraging the high-performance file system, they can significantly reduce processing time and gain a competitive edge in fast-paced markets.
In the scientific research domain, FSx for Lustre has revolutionized genomics research. Organizations involved in genomics analysis, DNA sequencing, and personalized medicine leverage FSx for Lustre to process massive genomic datasets quickly. Researchers can now perform complex computations, such as genome mapping and variant analysis, in a fraction of the time it would take with traditional storage systems. This has accelerated scientific discoveries and advancements in the field of genomics.
The impact of Amazon FSx for Lustre on reducing processing time and accelerating data insights is evident across a wide range of use cases. From machine learning and artificial intelligence workloads to high-performance computing and data analytics, FSx for Lustre empowers organizations to unlock the full potential of their big data. By minimizing data bottlenecks and providing lightning-fast data processing capabilities, FSx for Lustre allows businesses to make timely decisions, improve operational efficiency, and gain a competitive advantage in their respective industries.
Seamlessly Scaling with Amazon FSx for Lustre
Amazon FSx for Lustre provides organizations with the capability to seamlessly scale their data processing capabilities to meet the growing demands of their workloads. FSx for Lustre offers elasticity and flexibility, allowing organizations to handle large data volumes and varying workloads with ease.
One of the key advantages of FSx for Lustre is its elasticity. Organizations can easily scale their file systems up or down based on their specific requirements. As data volumes increase, FSx for Lustre can be seamlessly expanded to accommodate the growing workload without disrupting ongoing operations. This elasticity ensures that organizations can handle data-intensive workloads without experiencing performance degradation or capacity constraints.
Furthermore, FSx for Lustre offers flexibility in terms of performance and storage options. Organizations have the flexibility to choose the appropriate storage capacity and performance level based on their specific workload characteristics. This allows for optimal resource allocation, ensuring that the file system is tailored to meet the exact needs of the workload. Whether it’s high throughput requirements for data-intensive analytics or low-latency needs for real-time processing, FSx for Lustre provides the flexibility to adjust and optimize accordingly.
Provisioning and managing FSx for Lustre file systems is designed to be straightforward and user-friendly. With just a few clicks in the AWS Management Console or by using AWS APIs and SDKs, organizations can provision an FSx for Lustre file system within minutes. The file system is fully managed by AWS, eliminating the need for complex infrastructure setup or ongoing maintenance. This allows organizations to focus on their data processing tasks without worrying about the underlying infrastructure.
To optimize the use of FSx for Lustre for cost efficiency, organizations can leverage several strategies. Firstly, FSx for Lustre offers cost-effective storage options, allowing organizations to align the storage capacity with their actual needs. By efficiently managing the storage capacity, organizations can avoid unnecessary costs associated with overprovisioning. Additionally, FSx for Lustre provides integrated data compression capabilities, reducing storage costs further by optimizing the utilization of available storage space.
Furthermore, organizations can leverage FSx for Lustre’s integration with other AWS services to optimize cost efficiency. For example, organizations can leverage Amazon EC2 Spot Instances for cost-effective compute resources when running workloads on FSx for Lustre. By using Spot Instances, organizations can take advantage of unused EC2 capacity at significantly reduced prices, optimizing cost while maintaining high-performance data processing capabilities.
Best Practices for Leveraging Amazon FSx for Lustre
To optimize the performance and maximize the benefits of Amazon FSx for Lustre, organizations can follow several best practices and implement practical tips. These best practices encompass considerations for data ingestion, file system configuration, data protection, monitoring, and performance tuning.
Data Ingestion and File System Configuration
Data Layout: Organize your data in a manner that promotes parallel access and minimizes file system contention. Distribute data across multiple directories or subdirectories to take advantage of parallelism during processing.- Data Striping: Implement data striping by spreading the data across multiple OSTs (Object Storage Targets) to achieve higher aggregate throughput. Distribute data across OSTs based on the workload characteristics and access patterns.
- I/O Patterns: Optimize your I/O patterns by using larger I/O sizes that align with your workload. Minimize small I/O requests to improve performance and reduce overhead.
Data Protection
- Data Backups: Implement regular data backups and snapshots to ensure data resiliency and provide point-in-time recovery options. Leverage AWS backup services or utilize FSx for Lustre’s built-in backup and restore functionality.
- Replication and Multi-AZ Deployment: Consider deploying FSx for Lustre in multiple Availability Zones (AZs) for increased durability and availability. Replicating data across AZs can provide resiliency in the event of a failure.
Monitoring and Performance Tuning
- Monitoring Metrics: Leverage AWS CloudWatch metrics and FSx for Lustre-specific metrics to monitor the performance and health of your file system. Track metrics such as throughput, IOPS, and file system capacity to identify performance bottlenecks and optimize resource allocation.
- Performance Tuning: Continuously monitor and fine-tune your file system’s performance. Adjust settings such as Lustre striping, OST counts, and client configurations based on workload characteristics to optimize performance.
- Network Considerations: Ensure low-latency and high-bandwidth network connectivity between your compute instances and FSx for Lustre file system. Consider utilizing Amazon EC2 instances and FSx for Lustre in the same AWS Region or Availability Zone for optimal network performance.
Real-World Success Stories
Several organizations have successfully leveraged Amazon FSx for Lustre to achieve significant performance gains and accelerate their data processing capabilities. For example:
- In the media and entertainment industry, FSx for Lustre has enabled studios to process large-scale video rendering workloads, reducing rendering times from days to hours.
- Financial organizations have leveraged FSx for Lustre to accelerate financial modeling and risk analysis, allowing for faster decision-making and improved trading strategies.
- Genomics research institutes have utilized FSx for Lustre to reduce data processing time for DNA sequencing and analysis, leading to breakthroughs in personalized medicine and genetic research.
These success stories demonstrate the transformative impact of FSx for Lustre in various industries, showcasing the potential for organizations to achieve lightning-fast data processing and gain a competitive edge.
By following these best practices, organizations can optimize the performance of FSx for Lustre, ensure data protection, and maximize the benefits of high-speed data processing for their specific workloads.
Conclusion
In conclusion, Amazon FSx for Lustre provides a powerful solution for organizations to overcome data bottlenecks and unlock the full potential of their big data workloads. With its high-speed data processing capabilities, FSx for Lustre accelerates insights generation, reduces processing time, and empowers organizations to make timely, data-driven decisions. We encourage organizations to explore the capabilities of FSx for Lustre and leverage its transformative impact on their data processing workflows. Start your journey with FSx for Lustre today and experience the unparalleled speed and efficiency it brings to your big data initiatives.
A Software Engineer by profession and a Writer by passion